

コンテキスト化とは?
データには、21世紀の石油と言われるほど価値を生み出す可能性が潜んでいます。しかし、様々なシステムに保管されているデータは、それぞれのシステム内で利用されるように設計されており、システム間を跨って利用することは想定されていません。そのため、DXなど会社全体で取り組む施策の場合、そのままの状態(ローデータ)では何も意味がありません。
製造業、エネルギー産業で利用されるデータには下図に示すように、様々な種類があります。
- 装置データ
- P&ID・配管計装図
- IoTログデータ
- 時系列データ
- イベントデータ
- 3Dモデル

製造業やエネルギー産業ではこのような異なるタイプのデータが、複数のシステムにまたがって存在する(サイロ化されている)ことが一般的です。ここで注意しなくてはならないことは、それぞれ異なるシステムで管理されるデータには、システムを跨った関連性があるということです。例えば、工場にある装置情報であるポンプに対して、流量計のリアルタイムセンサーデータが時系列データとして関連付けられたり、また3Dモデルデータ、保守や検査履歴情報など多くの関連データがあります。企業にとって、データをより意味のあるものにし、データに価値を見出すにはこの繋がりを意識しなくてはなりません。


Cogniteでは、データのサイロを取り除いた上で、それぞれのデータの意味を理解し、データ同士を関連づけることをコンテキスト化(英語ではContextualization)と言います。
コンテキスト化の重要性
データが複数のシステムにサイロ化されており、データ同士の繋がりが明確ではない状況では、新しい用途のため、効率的な分析を行うためにはなど、1つのアプリケーションを作成するたびに、または1つの分析を行うたびに、異なるシステム間のデータを結びつける必要があります。そして都度作業を行う必要が生じ、そのソリューションを他の用途にも用いるためにはさらなる作業の追加が発生します。
Google社やマッキンゼーの調査によると、機械学習のモデル構築やアプリ開発などを行う上で、80〜90%の時間がデータ収集とクレンジングに消費されているというリサーチ結果もあります。そして、データのサイロ化によって産業界では75%もの時間が損失しているとの試算が出ています。これに対して、データの関連性が明確になった状況を保つことができれば、開発スピードが向上し、新しい発見が生まれやすくなると考えます。
つまり、DXを推進していく上で、コンテキスト化されたデータを準備・維持することは、即座にビジネス価値を生み出し、大幅な時間の節約につながるのです。
コンテキスト化によって恩恵を受けている身近な例は、グーグルマップです。初期のグーグルマップは単なる地図でしたが、そこに店舗情報、ルート情報、経過時間など多くの異なるシステムからデータを取り込み、それらのデータと地図の関連づけを行いました。これにより、優れたユーザーエクスペリエンスという利用者にとっての大きな価値創出がなされました。さらに、Uberなどグーグル社のパートナー企業向けにオープンなAPIを提供し、パートナー企業は、より便利なツールを迅速に開発することが可能になりました。皆様も、お店への経路や混雑状況などがひと目で分かる便利さを体感したことはあるのではないでしょうか。
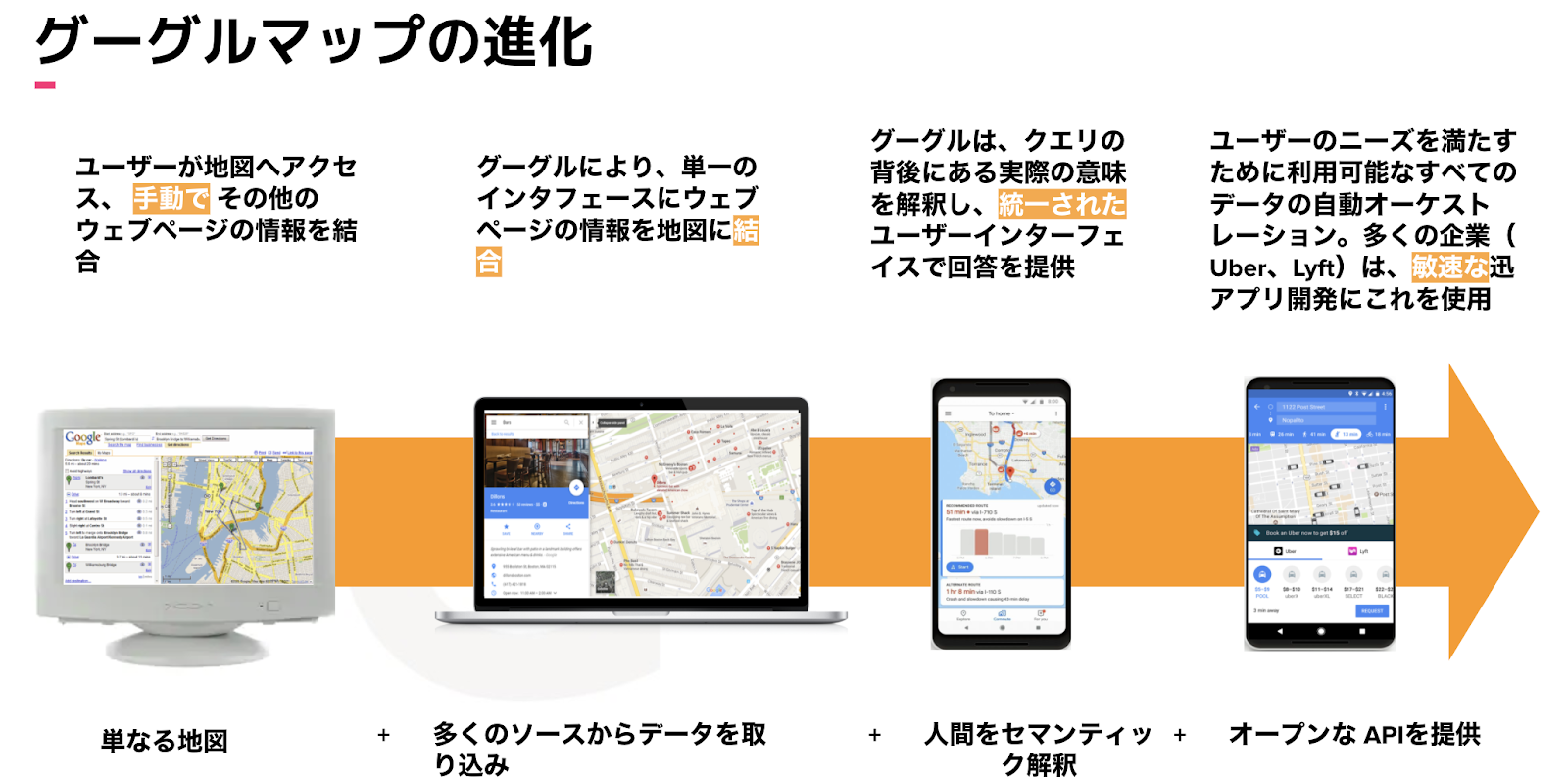
製造業やエネルギー産業でも、弊社のコンテキスト技術を利用することでグーグルマップと同じようなことが可能になると考えています。
後半で、製造業やエネルギー産業などの重厚長大産業におけるコンテキスト化データ使用事例を紹介しますが、データをコンテキスト化することで、生産最適化や、働き方改革、遠隔オペレーションなど様々なことが可能になります。
コンテキスト化を行う上での課題
コンテキスト化を行う上での1つ目の課題は、一般的にシステムやデータソースごとに装置を管理する名前(装置のタグ名)の命名手法が異なるということです。つまり、同じ装置に関連付けられるデータにも関わらず、装置のタグ名がそれぞれ異なるのです。
例えば、ある圧縮機の装置データがSAPに格納されており、その装置のタグ名が23-KA-9101-M01とします。一方で、同じ装置のセンサーデータが、OSIsoft Pi Systemにタグ名VAL_23_KA_9101_M01_Active_power_kW:VALUEで格納されています。

このように関連するデータ間で管理される名前が異なることが一般的であり、規則性に基づいたり、熟練者のノウハウによってこれらを結びつけるコンテキスト化を行う必要があります。
2つ目の課題は、一部のデータはPDF形式や紙媒体などコンピュータが処理しにくい形で保管されているということです。具体例として、P&IDまたは配管計装図は、配管プロセスと他の機器や計測器との相互作用を示すダイアグラムであり、通常PDF形式で保存されています。
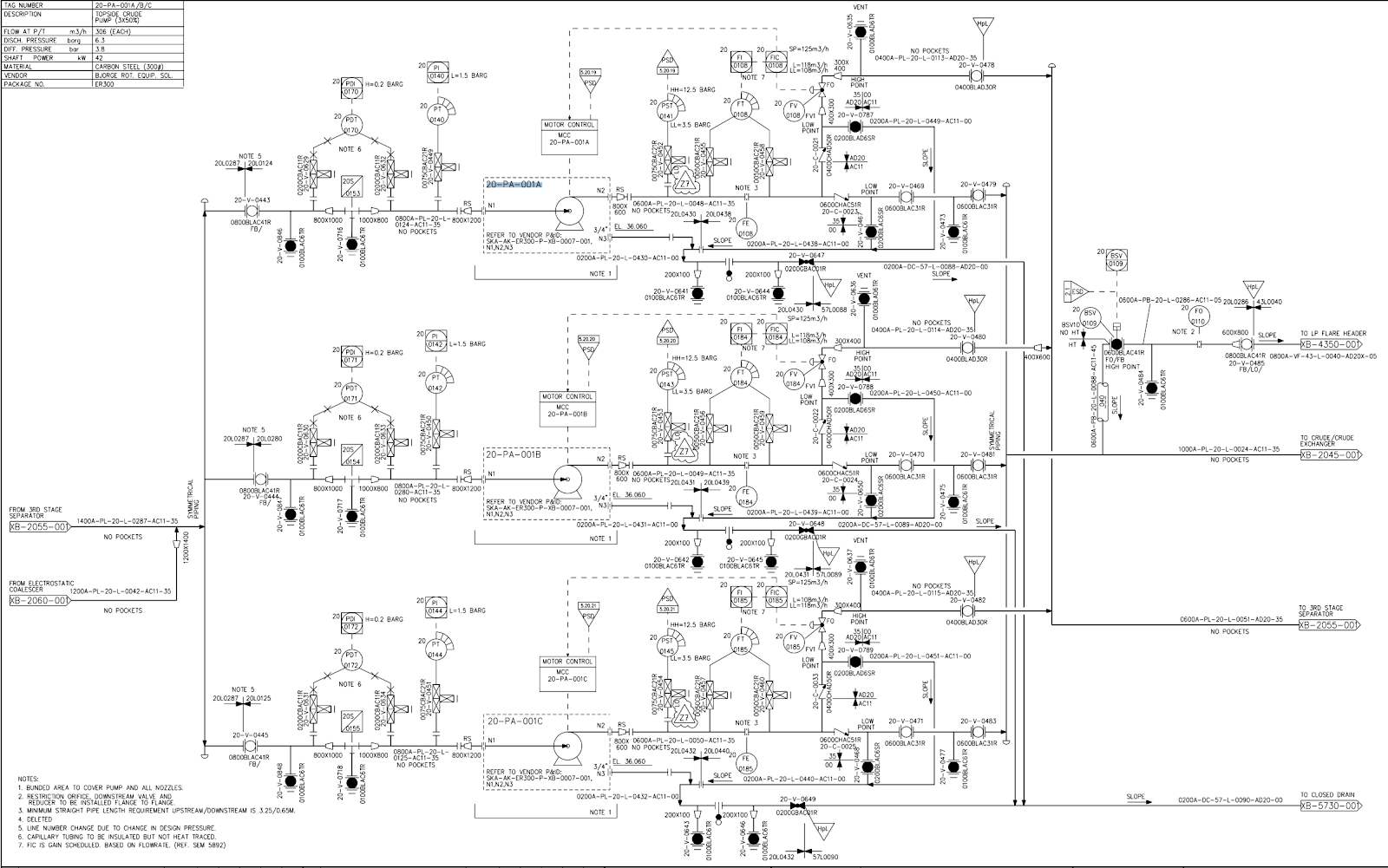
データのコンテキスト化を実現する上で、このようなPDFデータから情報を抽出し、センサーデータや3Dモデルなどのデータと結び付けなくてはなりません。
3つ目の課題は、製造業やエネルギー産業など重厚長大産業には膨大なデータ・装置が存在するということです。データ量や装置数が少ない場合、エクセルなどのツールを用いることでコンテキスト化を行うことも可能です。また装置数やデータ量が多かったとしても、PoC(仮説検証)の段階では全てのデータを使う必要がないため、手作業で行うことも可能かもしれません。
しかし、PoCを超えた実際の運用フェーズを考えた場合は、手動で行うことは困難を極めます。Cogniteのお客様の例では、60万以上の装置データ、60万個以上の時系列データ、1.9兆のデータポイント、400万個を越すイベントデータ、40万個以上のドキュメントが存在し、それらをコンテキスト化して活用しています。

上で述べたような複数の課題が存在し、コンテキスト化を手動で行うことは現実的ではないため、機械学習やコンピュータービジョンを用いた手法が注目されています。
機械学習で類似性・規則性を発見しコンテキスト化
機械学習によってデータ同士の類似性・規則性を見出し、スケール可能なコンテキスト化を実現することができます。
Cogniteのコンテキスト化の一連の処理は、次のような流れで行われます。
- 異なるシステムのデータ同士から機械学習を用いて規則性を発見
- 専門家による規則性・ルール確認と新規ルール作成により適合率を改善

上の動画では、タイムシリーズ(時系列データ)とアセット(装置)のコンテキスト化を例に挙げていますが、同じ要領で以下のデータ同士の組み合わせでもこの機械学習を用いたコンテキスト化を実行することができます。
- 装置 → 装置
- ドキュメント → 装置
- 3Dオブジェクトノード → 装置
- イベントデータ → 装置
- リストになっているデータ → 他のリスト
これにより装置(アセット)に対して他のデータをコンテキスト化することが可能になります。
コンピュータビジョンを使ったコンテキスト化
機械学習のみを用いたコンテキスト化には一つ弱点がありました。それは、P&ID(配管計装図)を始めとするPDF形式で保管されているデータをコンテキスト化することの難しさです。この問題を解消する上で重要なテクノロジーがコンピュータビジョンです。
P&IDをコンピュータビジョンを用いてコンテキスト化した例
処理前:

処理後:
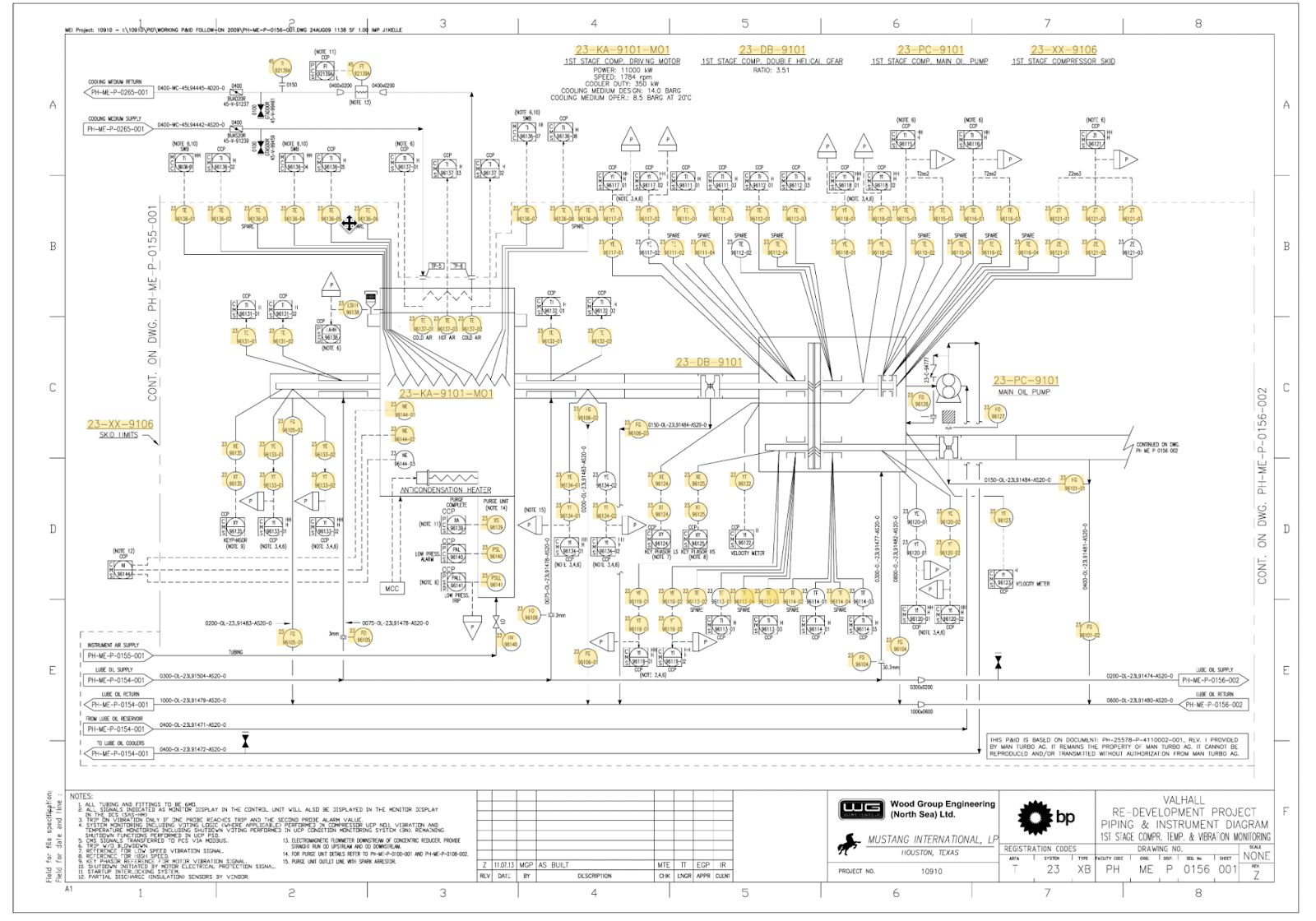
コンピュータビジョンのテクノロジーを用いてP&ID上に記載された装置のタグ名を自動認識し、情報を抽出します。色が変わった部分が、装置のタグ名に対してコンテキスト化が行われたことを示しています。注目すべきは、P&IDのタグ名は、連続した形で記載されている訳ではなく、記号と記号の間にシンボルが入っていたりします。それらをグループ化して、本当の装置のタグ名を抽出するのです。
また、機械学習によって装置データとセンサーデータもコンテキスト化されているため、P&IDとセンサーデータも結び付けることが可能になります。これらの情報を利用して、P&IDをスマートフォンのカメラを通して見ることで、装置を表す図形上にリアルタイムのセンサーデータを表示するARアプリケーションも登場しています。
コンテキスト化によりデータを有効活用しているお客様事例
製造業:横河電機がスマートメンテナンスを実現
横河電機は、Cogniteが提供するAIプラットフォームCognite Data Fusionを用いて、サイロ化されていたデータを統合し、コンテキスト化されたデータを用いることでスマートメンテナンスを実現しました。
Cogniteは横河電機の複数のシステムにまたがって存在する、時系列データ、機器データ、イベントデータ、取扱説明書などを2日で統合・コンテキスト化し、このデータ基盤を用いて、2つの側面から保守作業員をサポートするシステムを実現しました。
1つは、Cogniteのデジタルフィールドワーカー向けの主要アプリケーションであるオペレーションサポートです。コンピューターおよび持ち運び可能デバイスで利用可能なオペレーションサポートは、CDFからデータをストリーミングします。横河電機のメンテナンス作業員は、製造工場内の機器のタグをスキャンすることで、その機器に関連するすべてのリアルタイムおよび履歴データ、文書、メンテナンス記録、写真、その他の情報を引き出すことができます。
2つ目は、解放され、コンテキスト化されたデータと3Dモデルを組み合わせたデジタルツインです。甲府工場の写真を約400枚撮影した後、Cogniteはフォトグラメトリを使用して約30分で3Dモデルを作成しました。Cogniteはリアルタイムおよび過去のセンサーデータで3Dモデルをオーバーレイし、ユーザーにプラントを探索するための強力な視覚化ツールを提供します。
製造業:Aarbakkeが生産最適化を実現
Aarbakkeが保有する22,000個以上の切削機械に関係するデータをコンテキスト化し、可視化することで、10%切削機械の効率を向上させ、60%工具の削減に貢献しました。
Aarbakkeはもともと機械の稼働データや業務指示の記録を複数の独立したシステムに持っていました。そのためCogniteとAarbakkeはそれらのシステムから全てのデータを解放し、Cognite Data Fusionに集約することでダッシュボードにデータを可視化することができました。
このダッシュボードは、製造マネージャー、チームリーダー、作業員に、最も頻繁に使用されている機械の概要を提供し、機械が切り込んでいる素材に基づいて使用状況を色分けします。 Aarbakkeはこの情報を使用して、切削中の工具の使用を最適化し、切削時間を短縮できます。
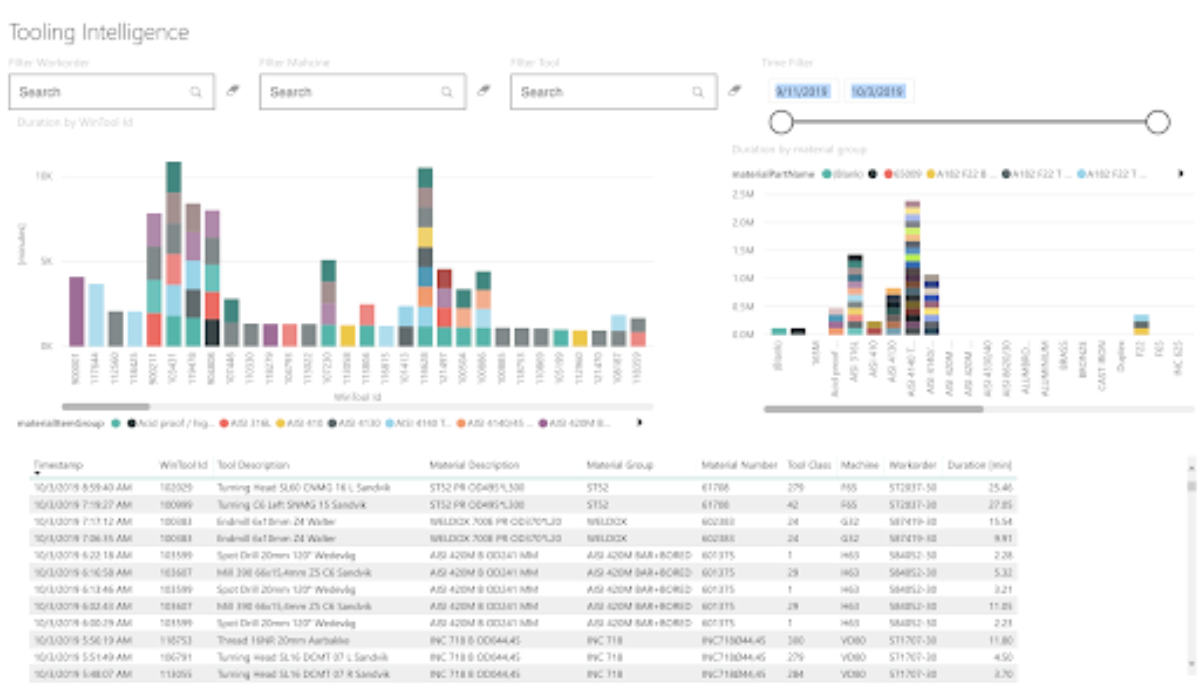
これを利用して、機械の過去の稼働データとそのパフォーマンスを分析することにより、Aarbakkeは工具を最大60%削減し、機械の効率を10%向上させることを目指すことが可能になりました。
石油ガス産業:Aker BPが3Dモデルを用いて保守作業の効率化・安全性向上を実現
石油大手企業Aker BPが活用できていなかった40万以上のドキュメントや15万以上の時系列データなどをCogniteがコンテキスト化し、そのデータを3Dモデルと結び付けることで、75%定期点検に費やす時間を削減しました。
石油ガスの現場は、数十万もの装置が存在するため、作業員がすべての機器の正確な位置を知ることは不可能です。作業員は多くの時間を機器の検索に費やしており、その結果、保守作業時間が伸びるとともに、潜在的に危険な現場で作業者が費やす時間が増加していました。
そこでAker BPはCogniteと協力して、全てのデータをコンテキスト化し、3Dモデルに結び付けることで、作業員はアプリケーションを用いて、機器タグを検索し、現場をデジタルの世界で確認することができます。これにより、周辺に機器をすばやく配置でき、実世界で機器を見つけるのにかかる時間を短縮できます。

コンテキスト化されたデータを用いることで、日本の製造業のデジタルトランスフォーメーションを次のステージに導くことが可能になります。次世代の工場に関するホワイトペーパーをダウンロードして、理解を深めていただけたら幸いです。
Cogniteのコンテキスト化のデモ動画(技術者向け)
注)英語での解説になります。また、Cogniteは日々製品の改良に努めているため、現在の製品とUIが異なる場合が御座います。