

Design
Time series databases typically come in two flavors: write-optimized and read-optimized. Cognite Data Fusion® Time Series Database (CDF TSDB) strikes a balance between the two, ensuring that tens of millions of data points per second can be ingested and read in response to queries simultaneously, reliably, and with ultra-low latency both for input/indexing and querying.
Write-optimized time series databases are useful as historians, constantly ingesting data from industrial equipment. But they are of limited use for large-scale analytics and are a poor choice to power interactive applications, as the stress from unevenly distributed user traffic may interfere with the reliable operation of time series ingestion. Examples include most industrial historians, as well as InfluxDB.
Read-optimized time series databases on the other hand are an excellent choice for analytical query loads, but struggle with streaming ingestion. They typically load batches of data and then do queries on stable data. Examples include TimescaleDB.
Performance
In addition to excellent read and write performance, CDF TSDB supports petabyte size (tens of trillions of data points) stored cost effectively without performance degradation. CDF time series is built using horizontally scaling technologies and can scale up in response to increased data and query volumes.
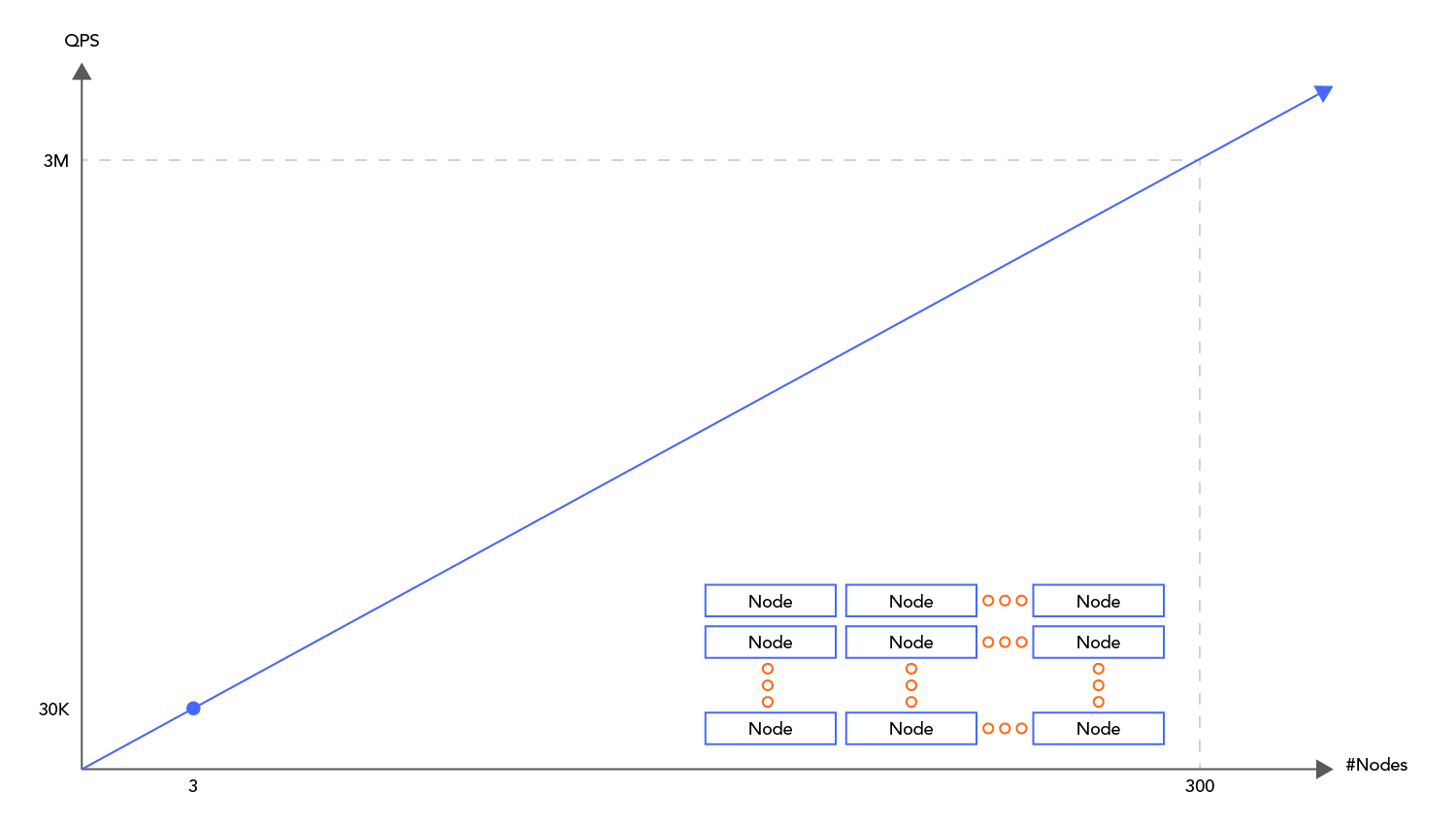
As of this writing, the largest Cognite Data Fusion® Time series cluster stores around 15 trillion data points, and is able to consistently handle 40 million data points per second ingested and 200 million data points per second read. We expect to be able to scale considerably higher than this.
Our performance tests on InfluxDB saw significant performance instability when performing reads and writes simultaneously, as would be the standard operating environment. We believe that this is due to the way compaction is working in InfluxDB. Read performance per node would fluctuate between 3k data points per second and 300k data points per second under heavy write load. Even assuming the highest range of read performance for InfluxDB, it came in at more than an order of magnitude more expensive than the CDF TSDB per data point read and written. While cost per data point stored was roughly 3x that of CDF TSDB.
TimescaleDB did not scale well on writes, nor to the amount of data needed.
Architecture
The architecture of CDF TSDB is based on a horizontally scalable NoSQL key value store with support for efficient forward and reverse scans (range queries) and transactions. The architecture balances immediate consistency on writes with high performance reads and reasonable cost.
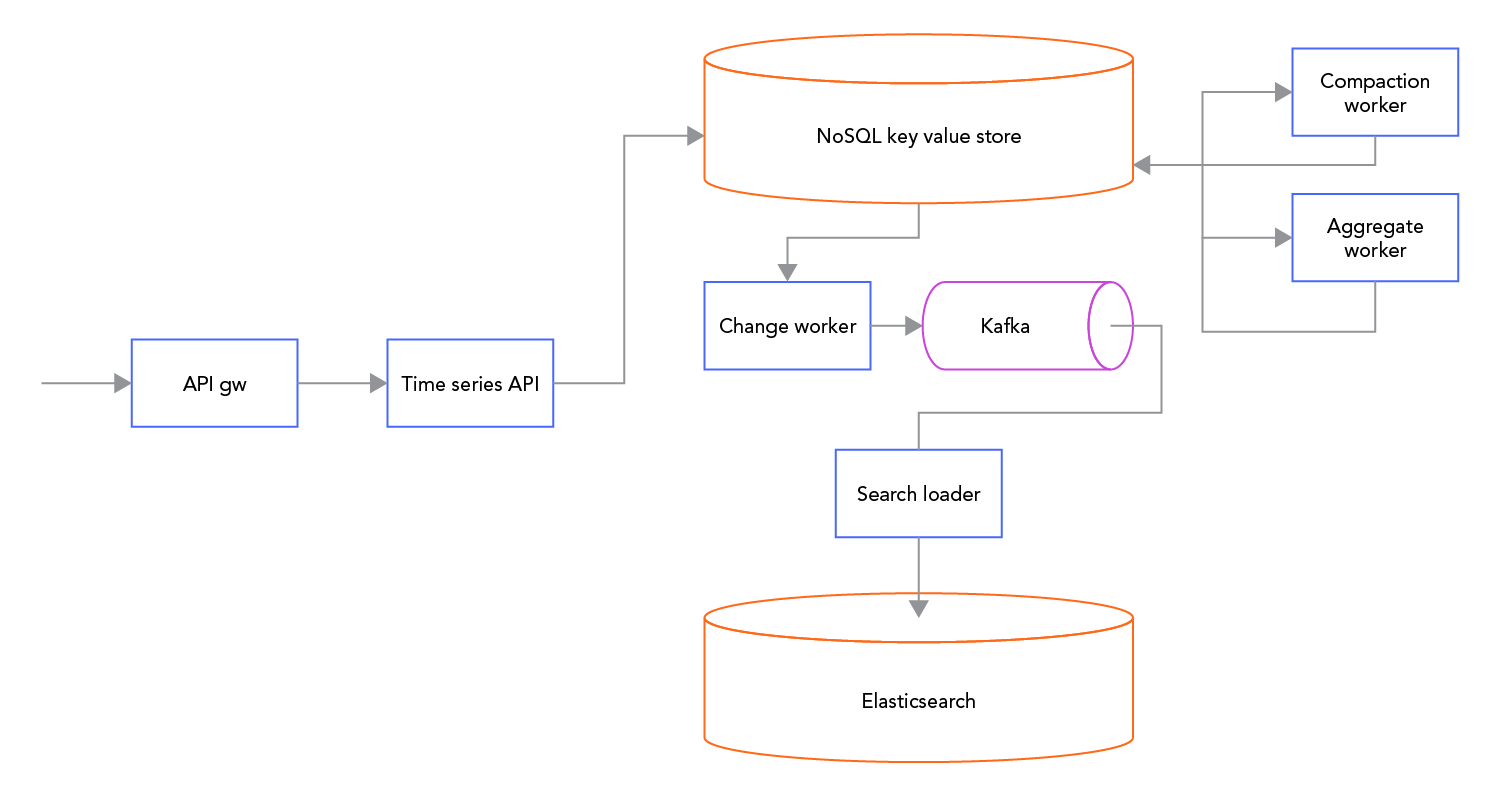
Time series data points are stored in blocks that cover dynamically sized time intervals to achieve optimal block sizes. Data is stored in two different storage tiers, for short term and long term storage respectively. Blocks are compressed losslessly resulting in roughly 3 bytes of data stored per data point (timestamp, value pair).
Data is pre-aggregated on ingestion to allow for efficient queries across vast amounts of data in large time intervals. Aggregates such as min, max, count, sum, average, variance and so on are computed on-the-fly for a dynamic tree of progressively smaller time intervals allowing for interactive performance on all queries. The asymptotic complexity of all queries is linearly proportional to the returned result size.
To further increase performance, CDF TSDB supports both JSON and protocol buffer encoded data. The OPC-UA and OSIsoft PI extractors that come with CDF use the protocol buffer binary protocol for increased performance.
CDF TSDB is instantly consistent on writes, meaning that all queries, including aggregate queries include data after a write returns a 200 OK response from the API.
Backups
Data is replicated 3-way to avoid data loss on node failures. This happens across availability zones in the underlying cloud infrastructure, making failures exceedingly rare. Data is also periodically backed up with snapshots for disaster recovery. Data points are versioned so that restores of data to the state of the database at any given time can be restored to +/- a few seconds (Recovery Point Objective).
Access control
Access control is managed through the customer’s identity provider. All access to the data is logged in immutable audit logs. Role-based access control is implemented, and access to time series data can be scoped to individual time series, specific data sets and root assets (typically representing a plant). Particularly sensitive data can be protected with security groups, which is a form of negative access grant which ensures that only users who are members of a particular security group can view this data, overriding other forms of access scopes. Combinations of these are also possible.
Roadmap
Nano-second support for data points is scheduled to be rolled out in 2022.
Learn more: Cognite Live Product Tour