
Offline and online evaluation methods for natural language query translation to GraphQL in Asset Performance Management (APM)
“There is a large class of problems that are easy to imagine and build demos for, but extremely hard to make products out of. For example, self-driving: It’s easy to demo a car self-driving around a block, but making it into a product takes a decade.” - Andrej Karpathy (Research scientist at OpenAI and former director of artificial intelligence and Autopilot Vision at Tesla).
Large Language Models (LLMs) don't know what they don't know. However, they still try to generate responses to the best of their abilities, often leading to plausible, though completely wrong, answers, making it difficult to implement trustworthy Generative AI for Industry.
This inherent limitation underscores the critical need for evaluating LLMs. As these models become increasingly integrated into various applications, ensuring their reliability, trustworthiness, and effectiveness is paramount. Without evaluations, you simply cannot know whether your LLM-based solution—whether it is prompt engineering, Retrieval Augmented Generation (RAG), or fine-tuning—is actually working, and neither can you improve it.
Evaluation strategies
Evaluations are a set of measurements used to check how well a model performs a task. An evaluation consists of two main components: benchmark data and metrics.
While there are many benchmark data sets available for LLMs, specialized tasks often require tailored data sets. For instance, if you want to use LLMs to generate a request body for your API service, you will need a dataset that includes examples of request bodies commonly used in your application domain.
Evaluation metrics are used to quantify the performance of the model on the benchmark data set. These metrics can broadly be classified into two main groups: traditional and nontraditional1-2.
- Traditional metrics focus on the order of words and phrases, given a reference text (ground truth) for comparison. Examples include exact string matching, string edit-distance, BELU3, and ROUGE4.
- Nontraditional metrics leverage language models' ability to evaluate generated text. Examples include embedding-based methods such as BERTScore5 and LLM-assisted methods such as G-Eval, where a powerful LLM is instructed to evaluate the generated text6.
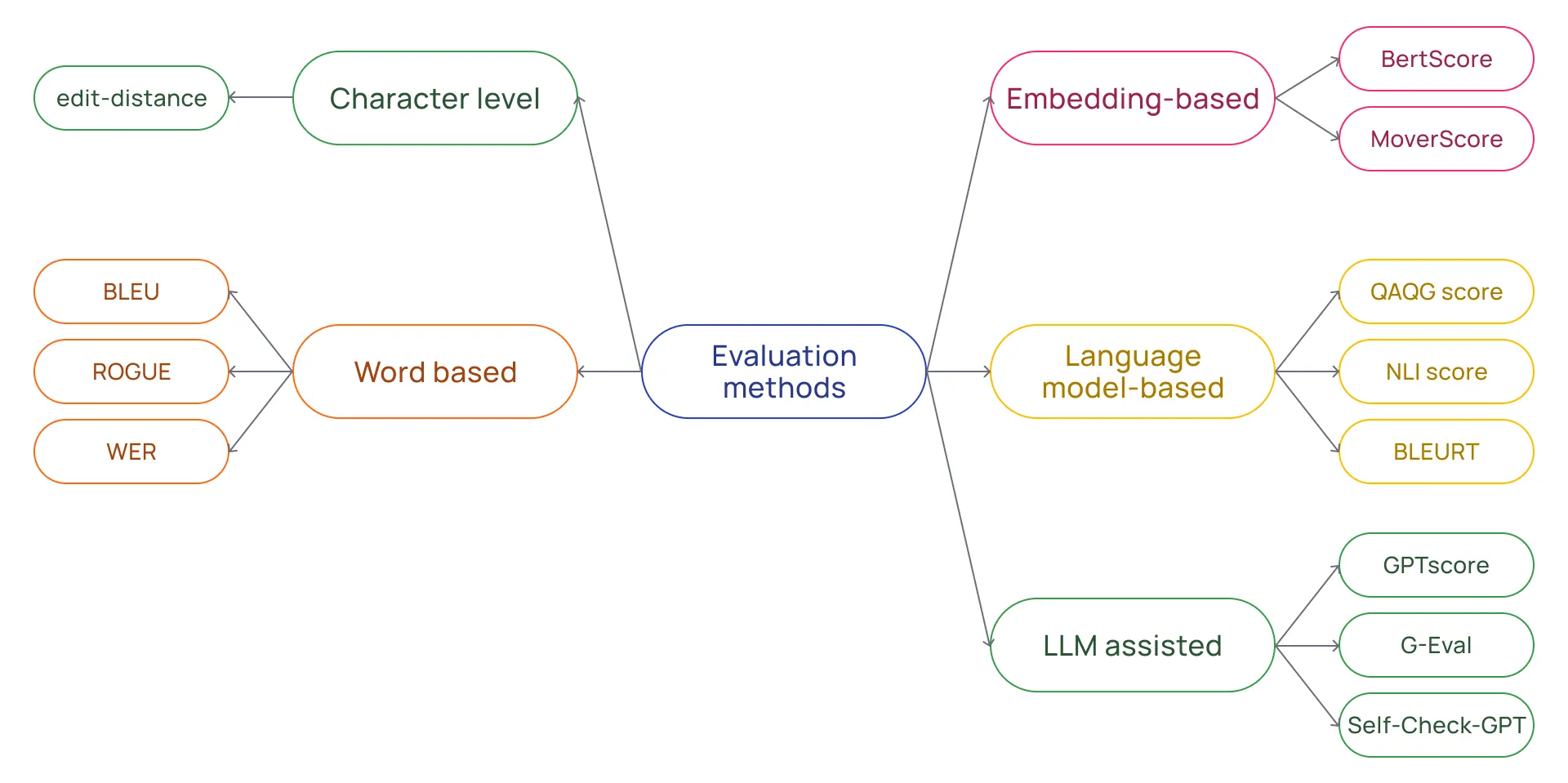
All about evaluating LLMs: Overview of various evaluation methods
While offline evaluation methods—i.e., methods where the performance of the system is estimated using pre-defined data sets, like the ones described above—are essential for ensuring that an LLM-based product feature has acceptable performance before deploying to users, they have their limitations and are usually not enough.
Creating high-quality benchmark data sets takes time, and your data set can get outdated after releasing a feature and no longer represent the type of tasks users ask about. In addition, offline evaluation may not fully capture the complexity of real-world user interactions.
This is why offline evaluation must be complemented with online evaluations: the continuous evaluation of LLM-based features as they operate in a production environment—in real-time, with real users and real data. After all, what matters most is whether the solution is actually useful for users in a production setting.
Online evaluation includes user feedback, which can either be explicit, such as when users provide ratings like thumbs up or down, or implicit, such as monitoring user engagement metrics, click-through rates, or other user behavior patterns. Note that both explicit and implicit feedback are important. Explicit feedback is generally more accurate and less noisy than implicit feedback, but it tends to be much less abundant.
To summarize, offline evaluations help you decide whether your LLM-based product feature has the minimum acceptable performance before deploying to users, while online evaluations are needed to ensure that your product continues to perform well in real-time user interactions, allowing you to monitor and improve its functionality over time based on live user feedback and behavior.
So, what does this look like in practice?
Example use case: Natural language query to GraphQL
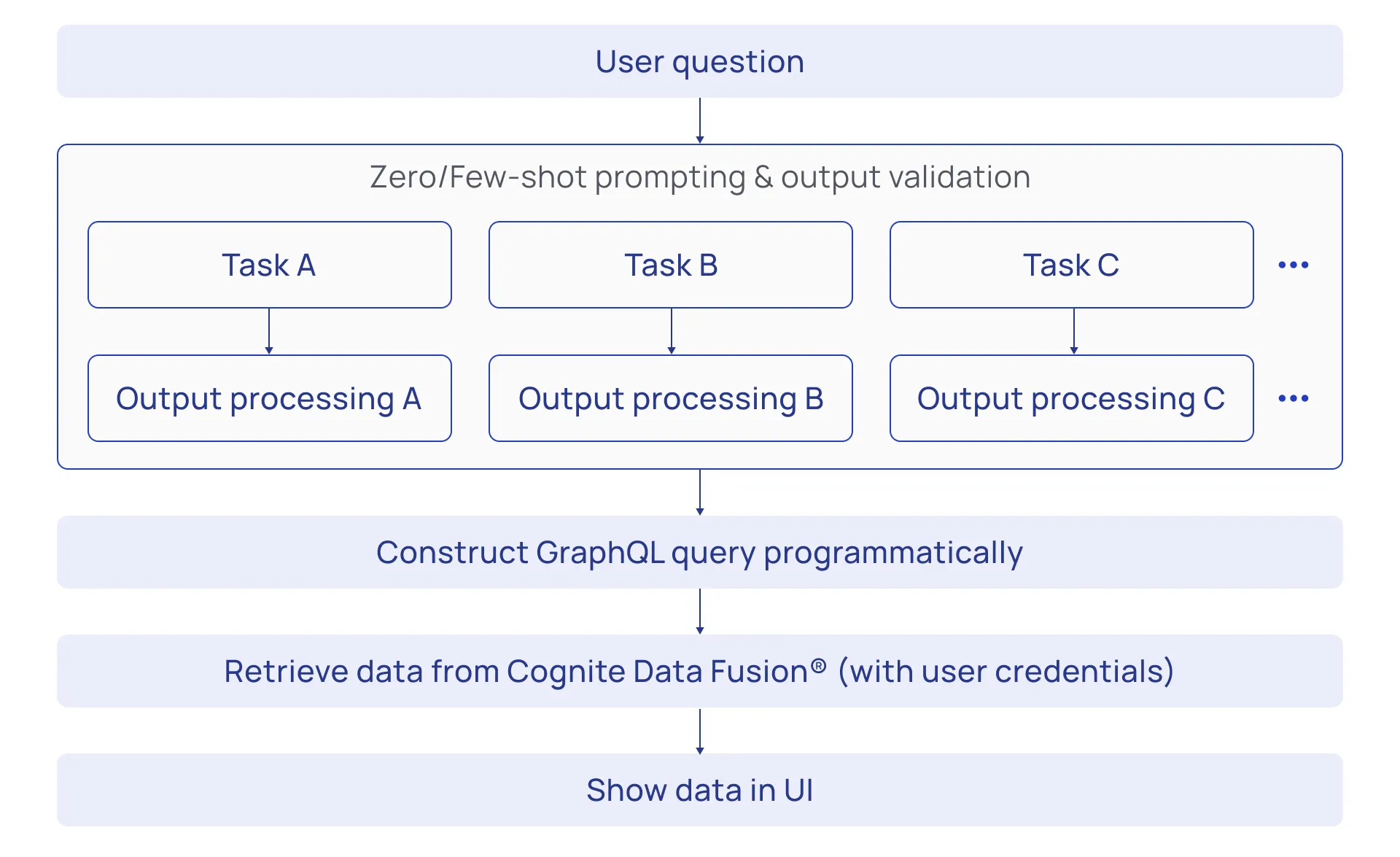
Natural Language question to GraphQL
One of the recent AI features added to Cognite Data Fusion®is the ability to search for data using natural language. Described at a high level, the user input or question is converted into a (syntactically correct) GraphQL query, which is then executed (using the user’s credentials) to retrieve data from Cognite Data Fusion®.
The conversion from natural language to GraphQL is done through a set of prompts—instructions for large language models to generate a response—where each analyzes different aspects of the question and returns specific components of the GraphQL query. For instance, one prompt is designed to propose a suitable query operation (e.g. get, list, or aggregate), another is designed to generate a suitable filter, and so on.
Each prompt also has a corresponding post-processing step to ensure the validity of the generated output. A simple post-processing example is, for instance, to check that the suggested query operation is a valid GraphQL query method. The outputs from all prompts are combined and used to construct a valid GraphQL query programmatically.
Benchmark data set
In order to evaluate the feature described above, multiple specialized data sets were curated with industry-relevant question-answers pair. Our benchmark data set includes around ten different Cognite Data Fusion® data models from sectors like oil & gas and manufacturing. Each model comprises tens to hundreds of real-life question-answer pairs, allowing evaluation across diverse scenarios. Below is an example test case from an Asset Performance Management (APM) data model:

question: different formulations of a relevant question, that all can be addressed using the same GraphQL query.relevantTypes: List of GraphQL types that are relevant to the question.queryType: The relevant GraphQL query and which type it should be applied on.queryType: Relevant filter.properties: Properties that are most relevant and should be returned given the context of the question.-
summary: A short description of the suggested GraphQL query.
Evaluation metrics
The prompts are evaluated using a mix of traditional and nontraditional methods. Simple string matching works for most fields, but for certain ones, like relevant properties, we calculate standard metrics (recall, precision, and F1 scores) by comparing suggested properties to the ones in the benchmark dataset. The summary field is evaluated with an LLM-assisted approach, where a powerful language model (GPT-4) grades the suggested summary, given the ground truth summary.
To monitor the model's performance, especially for changes in the underlying base model, we calculate evaluation metrics daily across all available datasets. These metrics are tracked in Mixpanel.
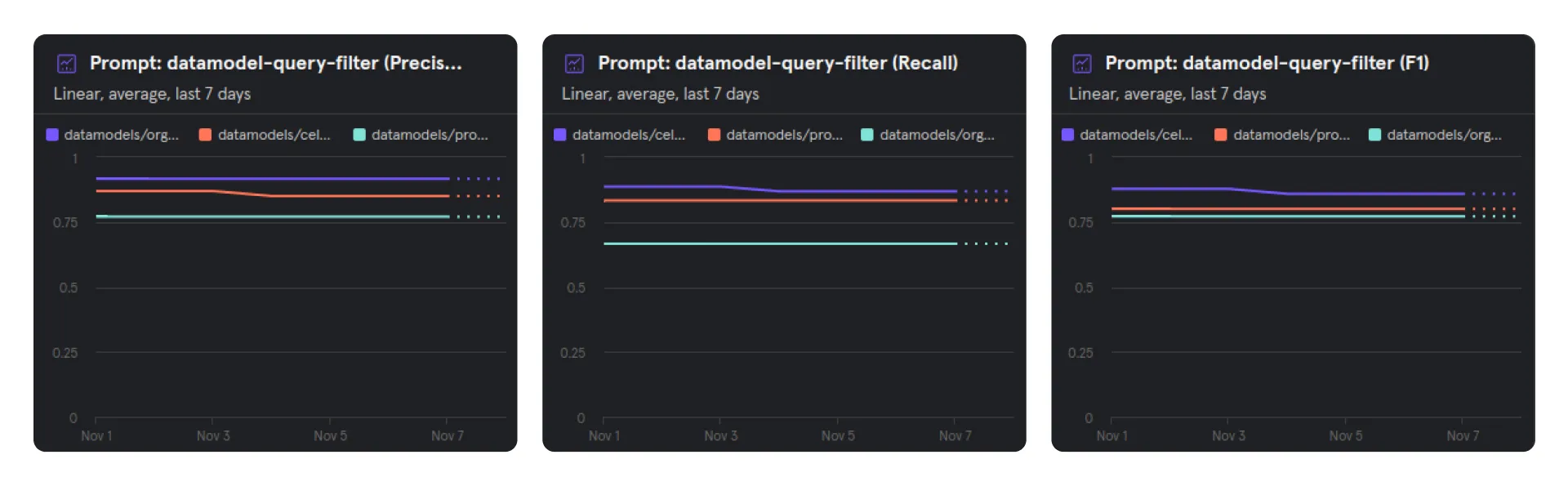
Monitoring of offline evaluation metrics in Mixpanel.
Furthermore, we created a suite of developer tools to support a rapid feedback cycle during the development of prompts and refinement of post-processing techniques. This suite comprises a Command-Line Interface (CLI) for assessing one or more prompts against a dataset or various datasets. It also includes a Continuous Integration (CI) system that intelligently identifies the necessary evaluations to perform in response to modifications in a pull request (PR). It then compiles a report directly on the PR page, offering complete insight into the impact of the changes on the evaluation metrics.
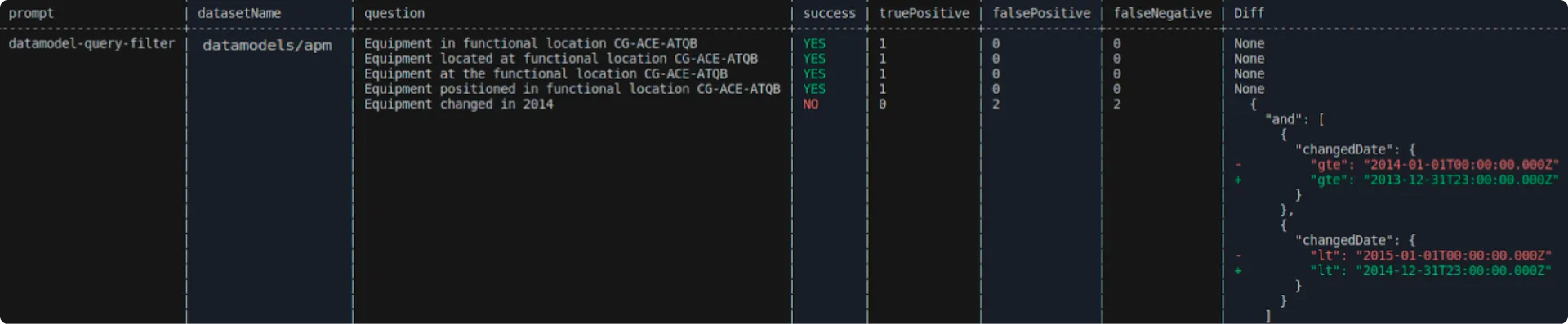
CLI tool for evaluating prompts on evaluation datasets

Report of evaluation metrics in a PR
Online evaluation
Evaluating a proposed GraphQL query for syntactical accuracy is relatively straightforward. However, determining its semantic correctness and usefulness is significantly much harder. In this context, a semantically correct query is one that retrieves relevant data based on user input or inquiry. To accurately gauge this—or, to be more precise, to obtain an indication of usefulness—online evaluation strategies are a necessity. A few example metrics that are collected for this particular use case include:
- Thumbs up and thumbs down ratings: Users can provide feedback through simple thumbs up or thumbs down ratings, indicating their satisfaction or dissatisfaction with the retrieved data.
- User modifications of suggested filters in the UI: Users might adjust the filters suggested by the system, tailoring the query to their specific requirements. These modifications may reflect that the suggested filter did not meet their expectations.
- User modification of the list of properties to display: Users might adjust the list of properties displayed in the result overview. These modifications may reflect that the properties shown initially did not meet their expectations.
In addition, several other performance and utilization metrics related to latency, error responses, and wasted utilization of the LLM—due to service errors or any other unactionable response—are also collected.
The online metrics serve as a foundation for evaluating the effect of modifications to the feature through A/B testing. In such tests, various iterations of the prompt sequences are distributed across distinct user groups to determine the most effective version. Variations may include using different LLMs, alternative prompts, or varied pre- and post-processing approaches. Moreover, these online metrics are instrumental in establishing Service Level Objectives (SLOs) for response times and end-user error rates, as well as user satisfaction measured via the satisfaction metrics mentioned earlier in this section.
Usefulness ≠ Correctness
It's important to emphasize that usefulness differs significantly from correctness. While correctness can be measured explicitly and objectively, usefulness is inherently subjective. Hence, the aforementioned metrics serve as indicators of whether users find the tool valuable or not. These metrics, derived from user interactions and feedback, offer valuable insights into the practical utility of the GraphQL query and help refine the system for optimal user satisfaction.
Interested in learning more about how Cognite makes AI work for industry? Check out The Definitive Guide to Generative AI for Industry →