

Using Retrieval Augmented Generation (RAG) with general purpose LLMs to get deterministic responses to natural language prompts from Industrial Data
Garbage in . . . Hallucinations out
Most of our early exposure to Large Language Models through Chat GPT, Dall-E, and other tools have exposed us to the incredible generative capabilities of this latest advancement in deep learning AI. The ‘Generative’ part of LLMs can be both a blessing and a curse. These models are trained to create new content (text, pictures, audio) following patterns they have learned during training. These generative results are, by design, plausible but not necessarily based on real facts in the absence of sufficient context. This is why we see such a tendency to hallucinate with responses that seem convincing but can be inaccurate.

However, there’s another side to Large Language Models that is often overlooked amidst the generative excitement. The ‘generative engine’ of Large Language Models is powered by an incredibly advanced ‘reasoning engine’. When harnessed and provided with rich contextualized industrial data, it is possible to use the ‘reasoning engine’ of LLMs to generate deterministic (fact based) answers to natural language prompts.
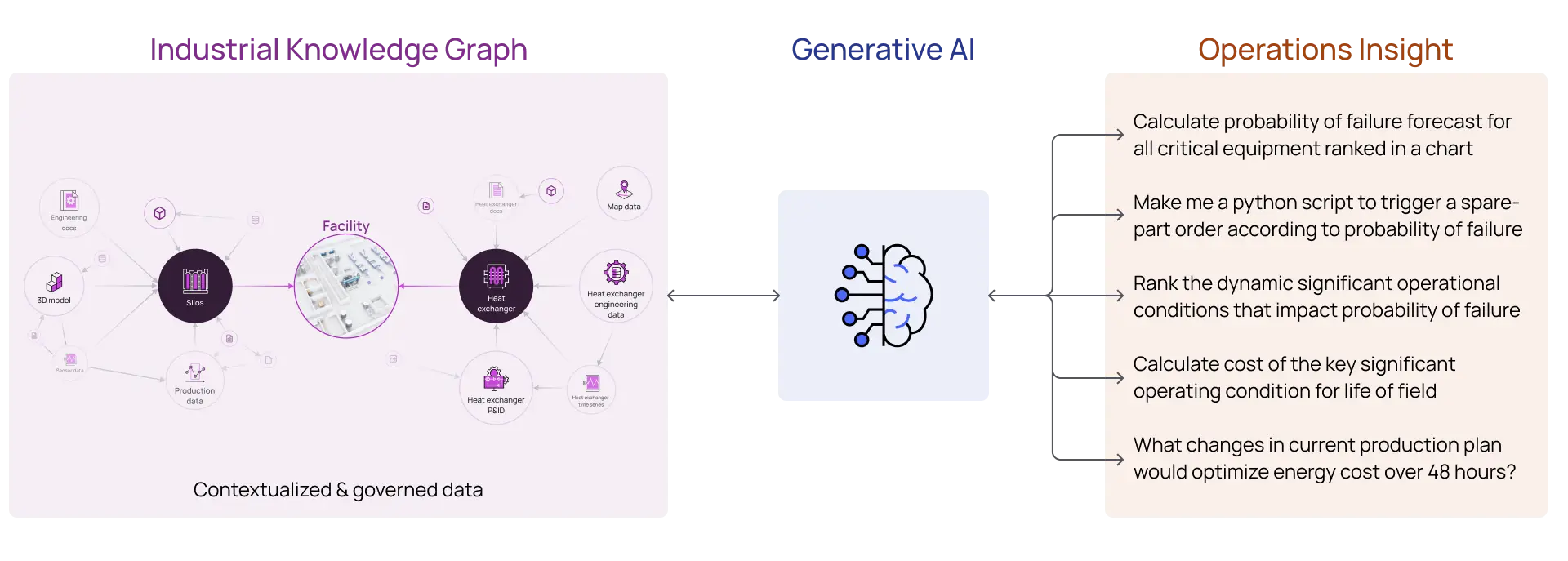
When a pre-trained model is provided with raw data in a data lake, the patterns and insights aren’t readily identifiable. These models, having been trained on text-based content, were provided the context that is inherent in natural language. Semantic relationships between words, sentences, and documents can be derived from the context of the content itself. However, Industrial Data is a complex mix of unstructured content in the form of P&IDs, technical documentation, images, video and reports as well as structured content from enterprise systems and time series sensor data. Context is no longer inherent in the data itself. If the semantic relationships among these highly varied data types can be added, we can leverage the ‘reasoning engine’ of LLMs to drive actionable insights.
RAG (Retrieval Augmented Generation)
Large Language Models have access to the corpus of text used during training of the model. However, these models can also take, as input, new information to incorporate when providing a response to a natural language prompt. This additional content can come in the form of real-time access to web-based queries of publicly accessible content or it can come from the user in the form of additional inputs as part of the prompt.
Retrieval Augmented Generation is a design pattern we can use with Large Language Models to provide contextualized industrial data directly to the LLM as specific content to use when formulating a response. This approach allows us to utilize the reasoning engine of LLMs to provide deterministic answers, based on the specific inputs we provide, rather than relying on the generative engine to create a probabilistic response based on existing public information.
In a previous blog we discussed how Large Language Models convert prompts and inputs into embeddings that it can use to drive the reasoning engine of the LLM. By taking proprietary industrial data and contextualizing this data to create an industrial knowledge graph, we can convert that enriched content into embeddings, stored in a private database, fine tuned for embedding storage and search (Vector Database). This specialized database of embeddings now becomes the internally searchable source of inputs that we provide to the LLM along with our natural language prompts.
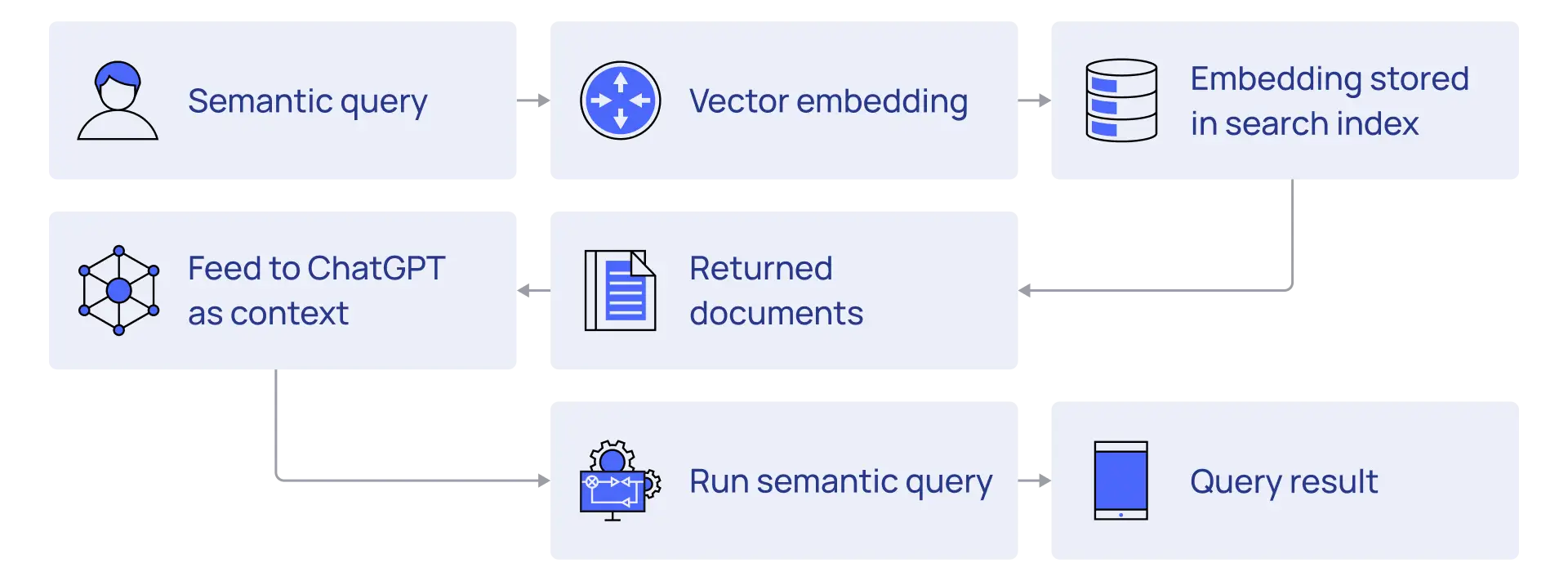
Codified Context to Drive Deterministic Responses
Simple aggregation of digitized industrial data is a significant step forward from the silos and inaccessibility that often plague large enterprises. However, in order to provide simple access to complex data we need to account for the variety of industrial data types and incorporate the semantic relationships that drive scalable utilization of this data in support of interactive user experiences. Codification of this context in the form of an Industrial Knowledge Graph is key to enabling consistent, deterministic navigation of these meaningful relationships.
By utilizing the open API’s of major LLMs we can then leverage this trusted source of industrial context to create and store embeddings in a way that becomes searchable (semantically) and enables us (with minor prompt fine-tuning) to fully leverage the reasoning engine of LLMs to give us actionable insights.
Leveraging this pattern, we can keep industrial data proprietary and resident within the security of your corporate tenant. We can maintain and leverage the access controls required to maintain trust, security and audit requirements of large enterprises. Most importantly we can get deterministic answers to natural language prompts by explicitly providing the inputs that LLMs should use when formulating a response.
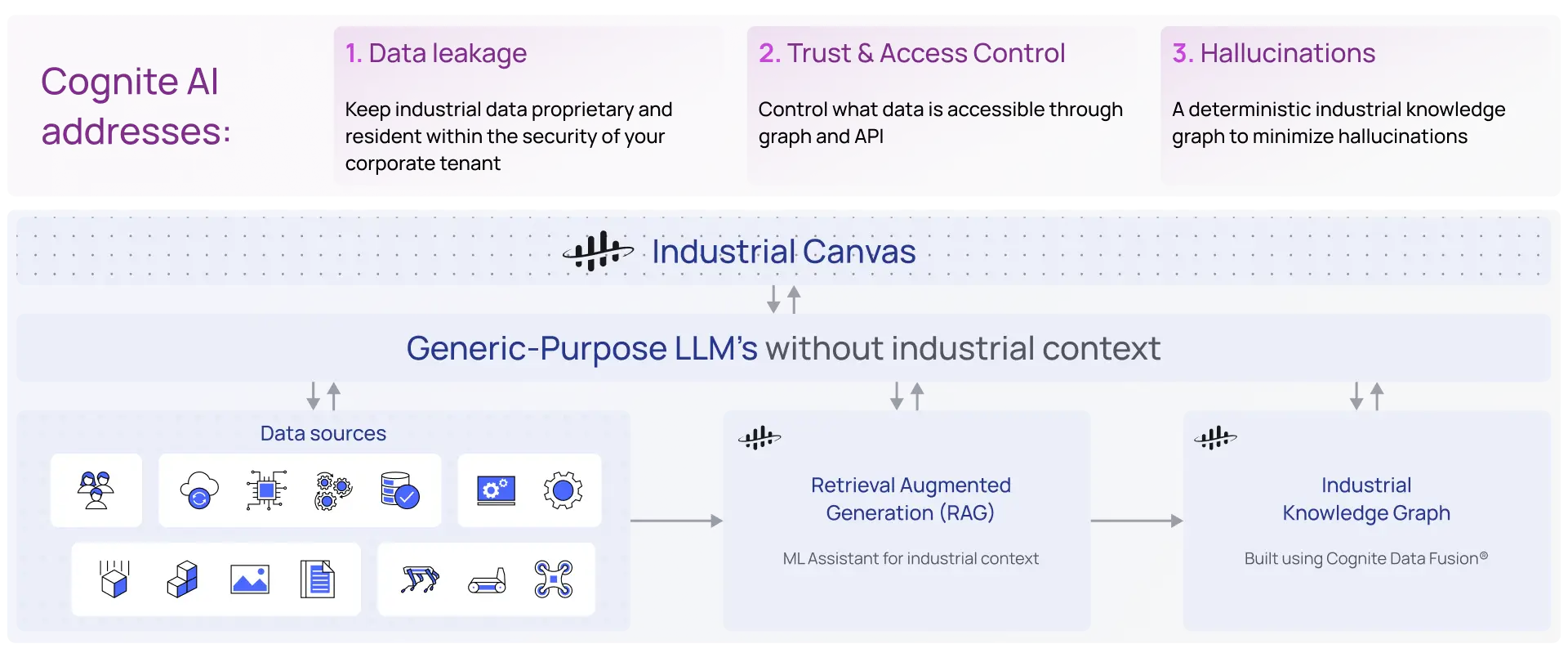
Does your Industrial Data Fully Leverage the Power of Large Language Models?
Retrieval Augmented Generation is just one pattern that enables an enterprise to leverage the reasoning engine of publicly available LLMs to drive trusted insights from complex industrial data. Generative AI technologies can also assist in the process of data modeling and contextualization as well as delivering low-code / no-code access to insights that previously required higher levels of domain expertise and software development proficiency.
Codification of industrial data, across the wide variety of structured and unstructured data types will drive the next generation of industrial data operations, powered by AI.
