

Achieve a compounding data advantage with the powerful combination of contextualization, digital twins, and Generative AI.
Drowning in data
When it comes to liberating data from siloed source systems, most industrial organizations make the mistake of not thinking beyond a data lake to solve the industrial data problem.
Data lakes are a conglomeration of untransformed, raw data. Subject matter experts still can’t find the data they need, they don’t trust its quality, and they certainly can’t use it to make high-impact decisions.
“Data has no value unless the business trusts it and uses it.”
Forrester
While some applications benefit from raw data, most applications — especially low-code and no-code application development — require data that has undergone some additional layer of contextual processing. “Human contextualization” is still necessary, which is feasible to do with a limited scope but impossible if you want to scale your digital and data investments.
'Our site engineering folks are doing data contextualization manually again and again as per today. How can we automate data contextualization to enable us to do multiple things faster, well governed, and each time building upon prior work?
- Digitalization executive at large downstream company
So what is required to transform “data swamps” into contextualized data havens that fuel operations insight at all levels of the organization?
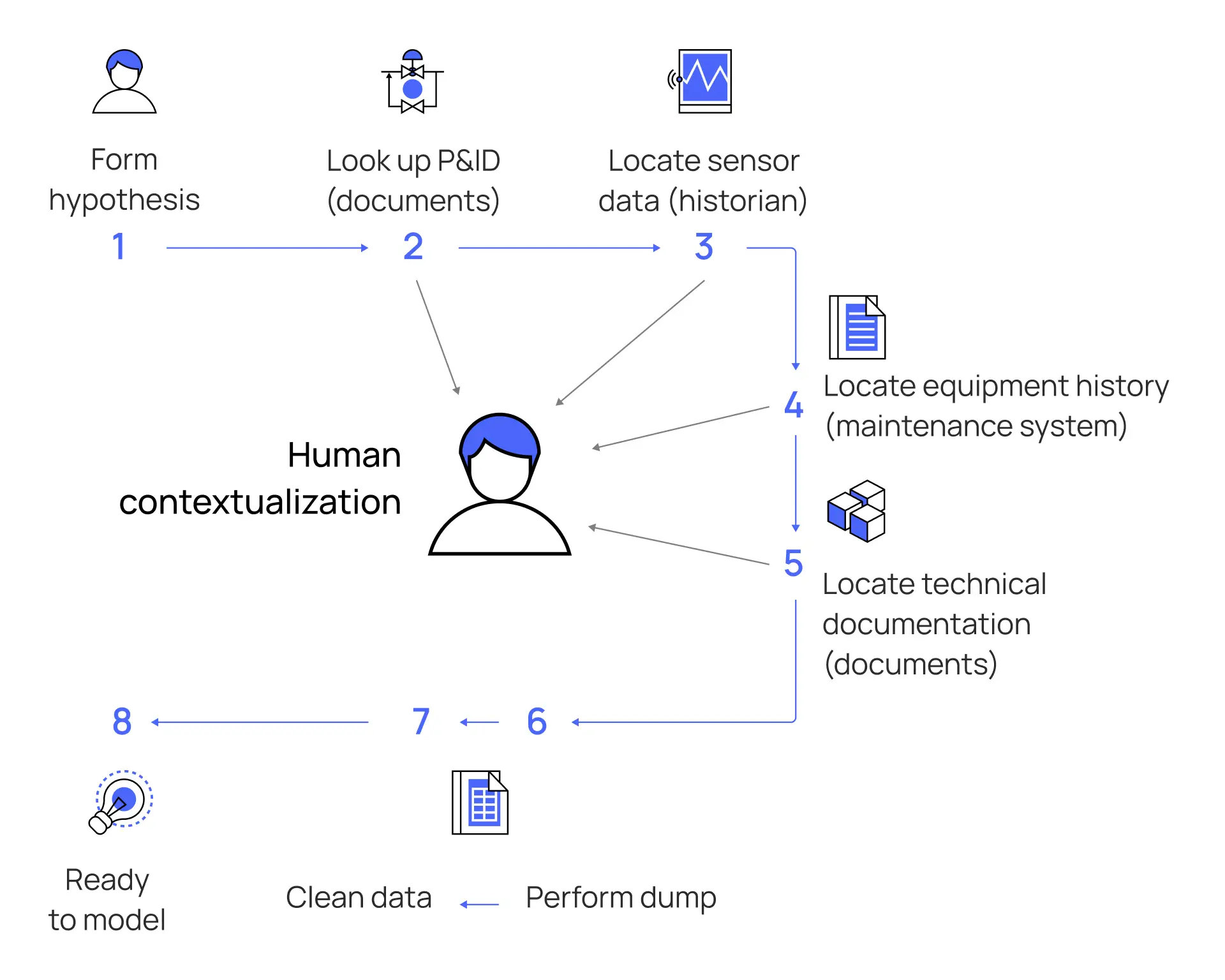
Saved by context
Contextualization is the process of identifying and representing relationships between data to mirror the relationships that exist between data sources in the physical world. The ability to construct these relationships and populate an industrial knowledge graph is paramount to a successful data strategy. It is this industrial knowledge graph that serves as the foundation of an Open Industrial Digital Twin.
An Open Industrial Digital Twin is the most powerful and practical application of data contextualization. Digital twins are fantastic tools for communicating the potential value, improving day-to-day activities, streamlining workflow and discovering more opportunities and solutions when powered by liberated, enriched, and contextualized data.
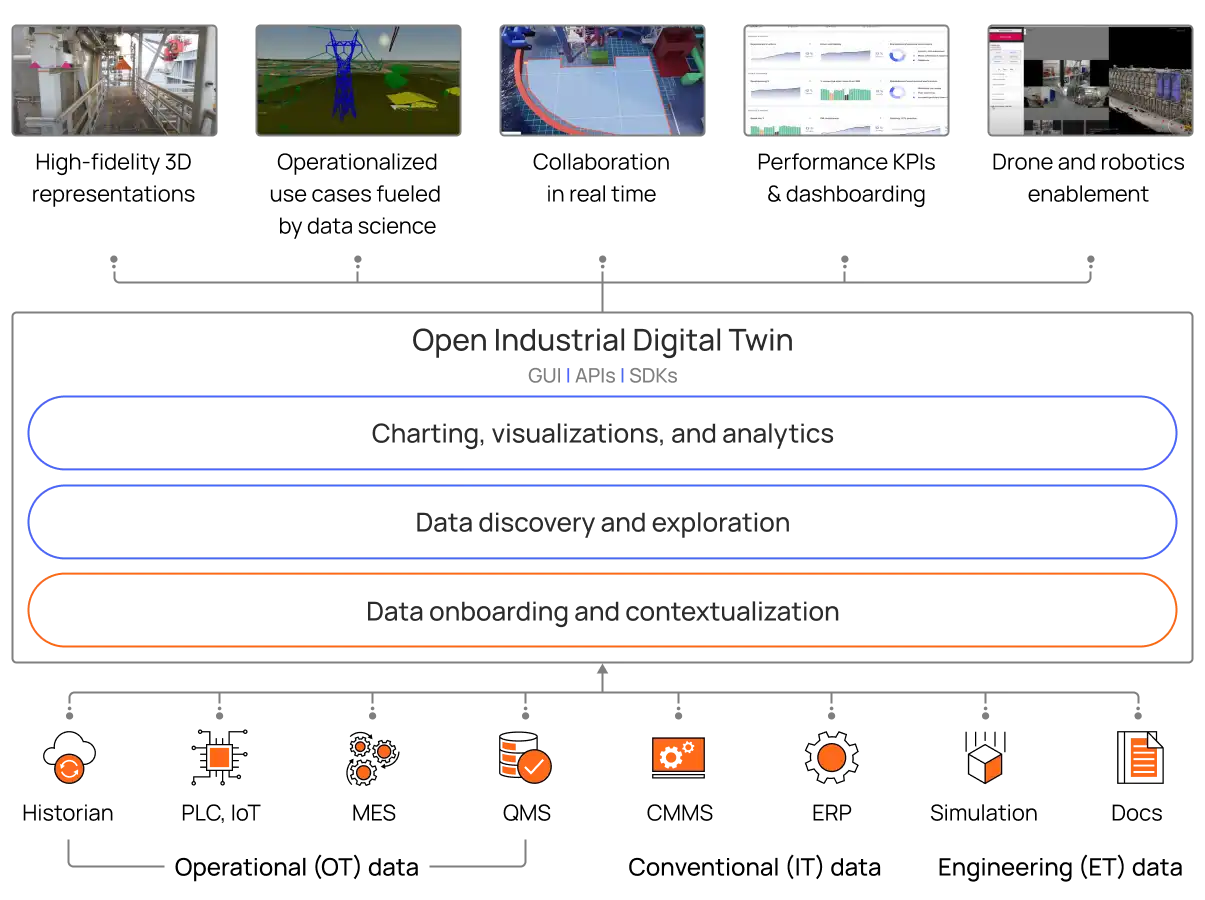
Not all digital twins are created equal. Both people and AI rely on data they can trust. Learn more about why Cognite Data Fusion achieves industry-first DNV compliance for digital twins and is quality-assured for use in real-world industrial organizations.
Contextualized data generates immediate business value and significant time-savings in many industrial performance optimization applications, as well as across advanced analytics workstreams. Plus, access to contextualized data allows subject matter experts to become more confident and independent when making operational decisions or when working on the use cases with data scientists and data engineers.
Contextualization helps solve the complexity of industrial data but once this is all done, the question is, how do we then use this data? Generative AI will change the way data consumers interact with data, enhancing self-service and potentially making some workflows humanless, but will or can it completely eliminate “human contextualization”?
Enhanced by Generative AI
Generative AI, such as ChatGPT/GPT-4, has the potential to put industrial digital transformation into hyperdrive.
Whereas a process engineer might spend several hours performing 'human contextualization' (at an hourly rate of $140 or more) manually – again and again – contextualized industrial knowledge graphs provide the trusted data relationships that enable Generative AI to accurately navigate and interpret data for Operators without requiring data engineering or coding competencies.
However, while Generative AI can help to make your data “speak human,” it won’t necessarily speak the language of your industrial data. A strong industrial data foundation is required to remove the risk of “hallucinations,” or a response by an AI that is not correct or justified by its training data.

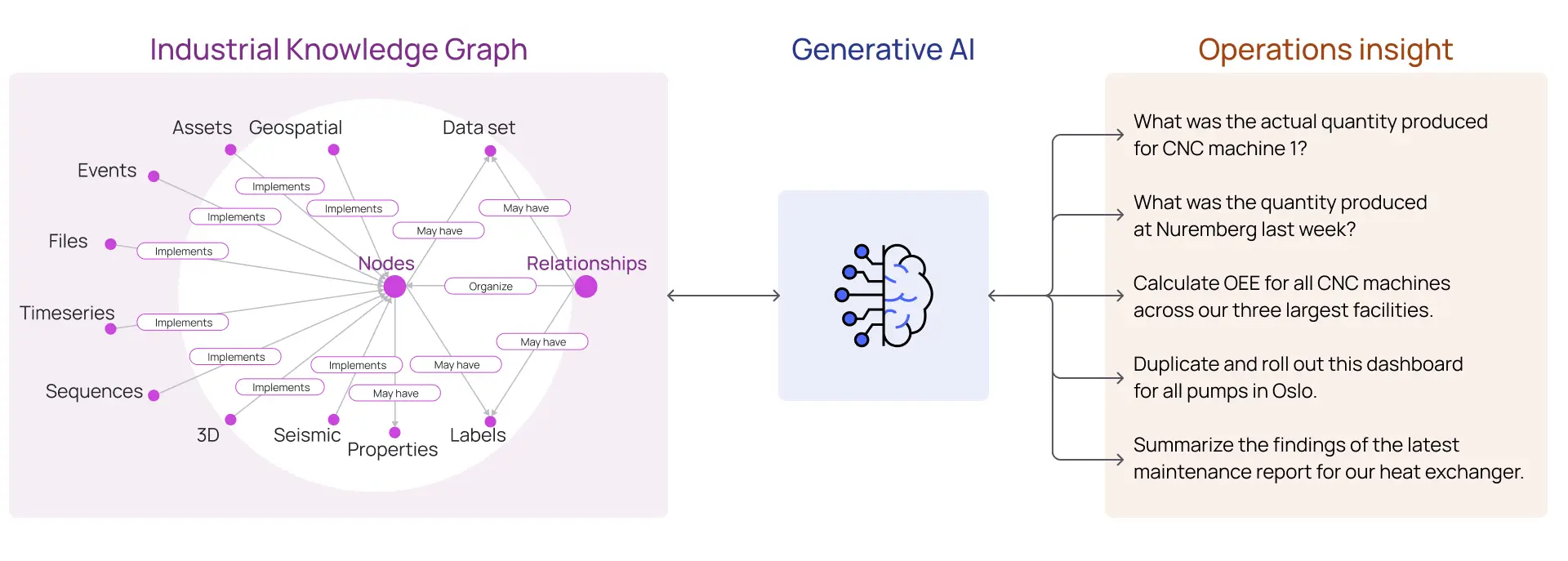
This is why an Open Industrial Digital Twin is a necessary prerequisite in any digital strategy that incorporates Generative AI. A digital twin provides the industrial knowledge graph, which serves as the reliable foundation for Generative AI technologies to form an accurate understanding of your organization’s industrial reality. As a result, people across the enterprise can confidently gain valuable insight into operations.
What used to take your process engineers, maintenance workers, and data scientists hours of precious time will take only a few seconds with Generative AI-powered semantic search.
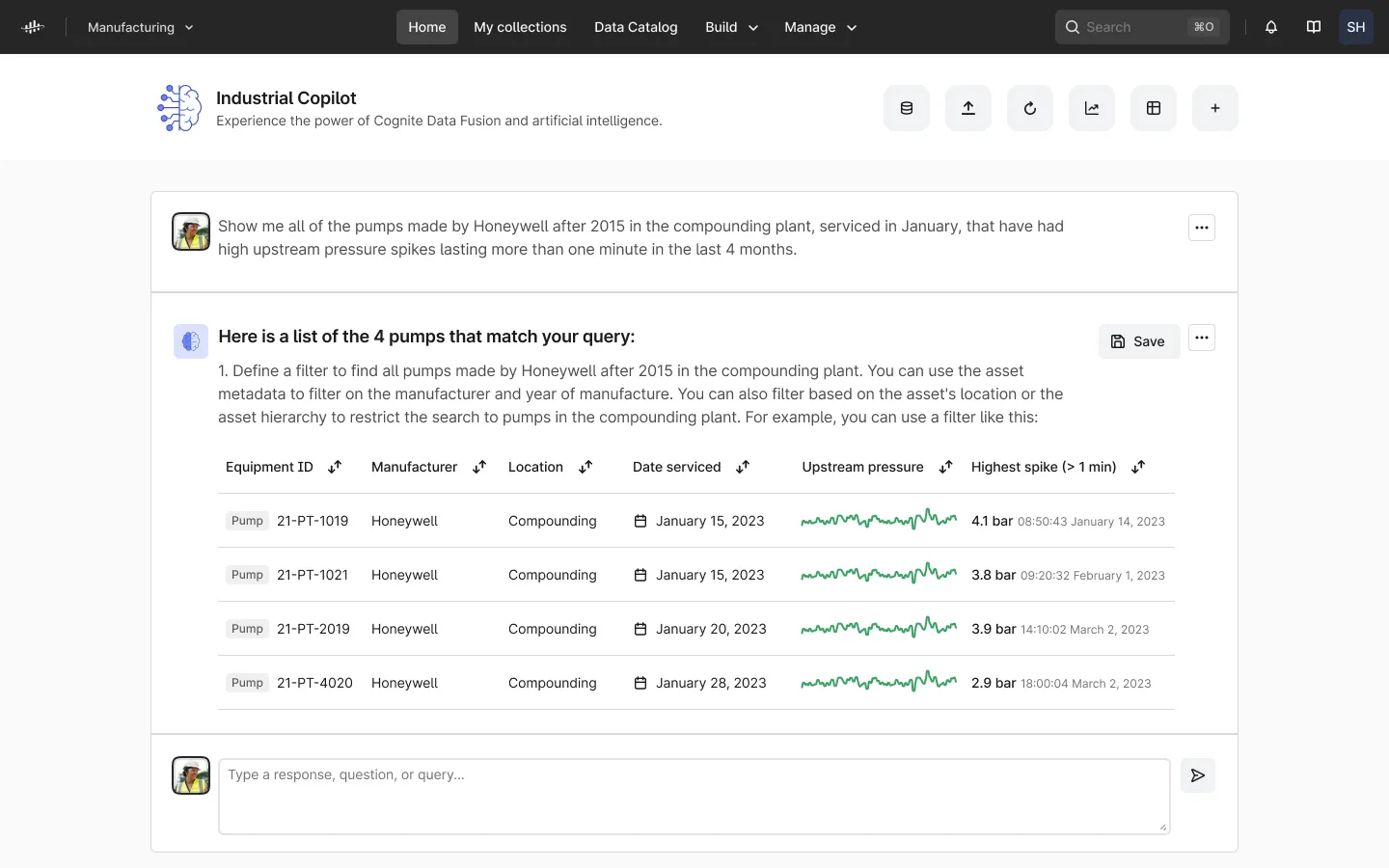
Cross-data source insight is more valuable than insight from a single source. It enables people at all levels of an industrial organization to gain a complete understanding of real-world operations and processes. This leads to better insights, faster decisions, and triple digit returns on investment. In particular, this cross-data source insight is powerful for Asset Performance Management, which inherently spans across the domains of maintenance, operations, and reliability.
A compounding data advantage
While AI-powered contextualization is compelling, the true power of the new Generative AI technologies is in its ability to codify human expertise by creating new and better data.
We’ve already seen how OpenAI’s GPT-4 and Codex can turn anyone into proficient coders, no prior experience required. Emboldened by this technology, subject matter experts – the ones who have the most industrial knowledge, but lack coding experience – are able to create calculated time series, build dashboards, generate code, and so much more. Converting their decades-long relationship with equipment and production processes to cross-data source insights that scale with the stroke of the keyboard.
As more people use and enrich the Open industrial Digital Twin, the quantity and variety of data in the digital twin becomes richer and more valuable than all other data sources combined.
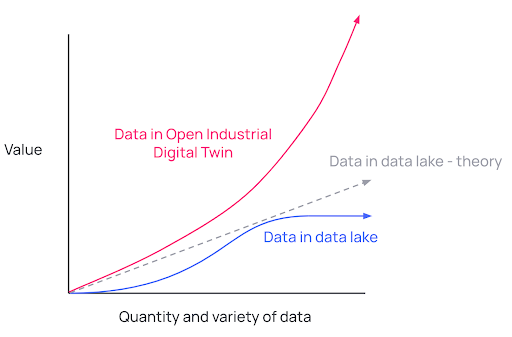
Just like the principle of compounding interest, the data in the Open Industrial Digital Twin becomes increasingly more valuable the more people use, leverage, and enrich that data. More valuable and high-quality data leads to more powerful insights. More powerful insights that data consumers can trust lead to higher levels of adoption across the enterprise. And a user-friendly, AI-powered experience ensures adoption and use will continue, and this cycle will repeat at an exponentially increasing rate.
In a data lake, there is a more linear relationship between the quantity data you ingest and the additional value the added context provides. This value often plateaus after a certain point, even when additional data is ingested. True compounding value lies in the ability of the new data to enrich already existing data, improving overall data quality and relationships, and, ultimately, power trusted and actionable insights.
We at Cognite believe the most valuable insights are achieved by putting all of your complex industrial data in context and making it simple for people to access, use, and enrich that data.
We'll continue to discuss the impact of Generative AI on the industry and will try to help you get a better understanding of how you can make the most of this game-changing new technology. If you don't want to miss our next post on this topic - make sure to sign up for our newsletter or contact us with feedback or questions.