

Connecting DWH to advanced analytics at scale requires a data fabric, not just data availability.
For industrial companies, the path to ultimate value from data liberation requires three crucial steps. Many organizations have already achieved step one: liberating data from siloed source systems and aggregating it in a traditional data warehouse (DWH).
The bad news: Step two is far more difficult to achieve. The good news: The rewards for successfully taking it are correspondingly higher.
In today’s mature DWH market, progressive data-driven organizations are actively utilizing data fabric solutions as a complement to existing DWH strategies. With data fabric, organizations can liberate their data once again. Lifting it from the pool of aggregation and turning it into contextualized knowledge to deliver on their ambitions for advanced analytics.

What is data fabric? And what sets it apart from data warehousing?
The two main pillars of data fabric are Context and Discovery. These define data fabric and make it both distinctly different from and complementary to existing DWH.
1. Data context is the sum of meaningful use case supportive relationships within and across different data types and data artifacts. It is the result of data relationship mining and curation in a so-called contextualization pipeline. The process of adding context to data is often referred to as data contextualization or data fusion.
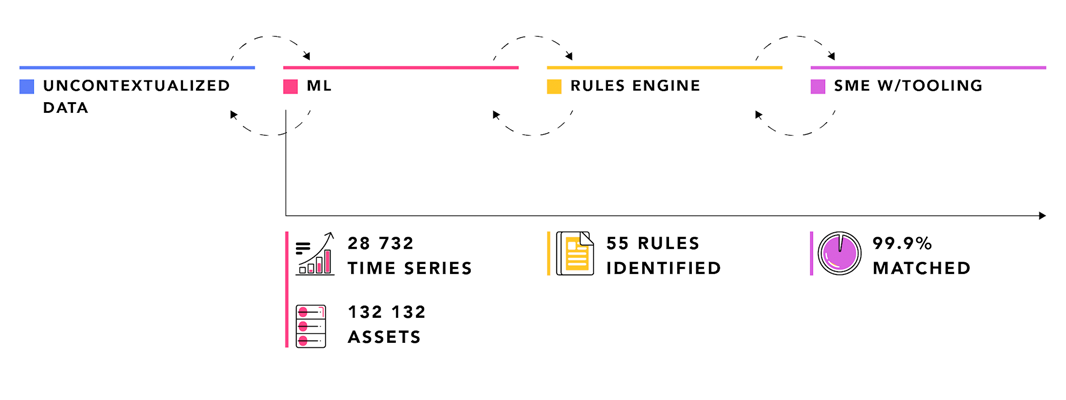
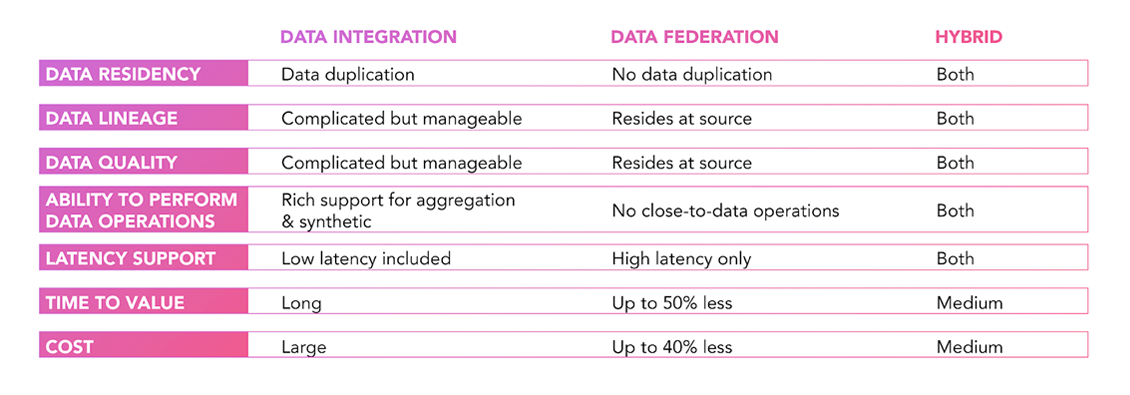
Prior to contextualization, data is often integrated from a multitude of source systems and co-located in a common data repository, similar to traditional DWH. Alternatively, data integration is virtualized through data federation, avoiding the need for data duplication and transfer. More recently, a hybrid approach has become common, especially for latency-sensitive IoT data applications, where data aggregation and data synthesis must be performed close to the data.
Read also: The data liberation paradox: drowning in data, starving for context →
What is the industrial status quo?
In oil and gas, digitalization efforts have long been limited to pilot projects, proofs of concept and case studies, with no large-scale operationalized projects. This is mainly due to outdated IT infrastructures that rely on legacy systems and only enable point-to-point integrations for application providers. These one-off solutions–sometimes including limited digital twins–can actually complicate digitalization goals because the resulting projects are as siloed as the original data, making them impossible to scale and, therefore, costly to the point of wastefulness.
Complementing existing DWH solutions with data fabric has dramatically reduced costs, while simultaneously enabling scalability, speed of development, and data openness throughout our many complex customer organizations.
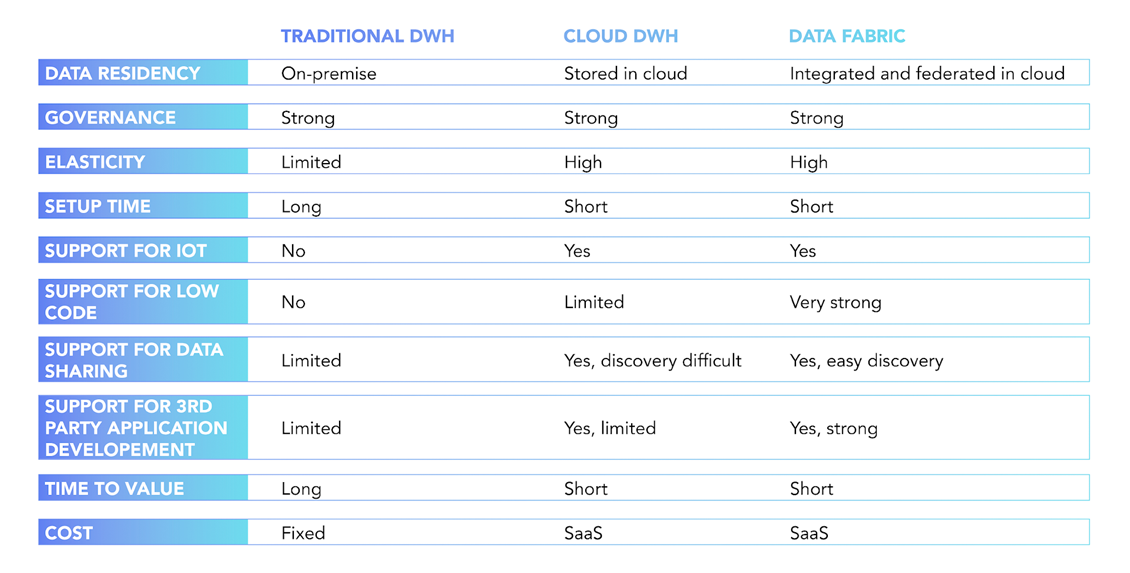
2. Data discovery is about making data effortlessly available to the right user in the right format. This has always been the goal of data and information architects. Discovery in B2C technology is instantaneous, autonomous, and continuously self-learning. In other words, it’s far ahead of enterprise and IoT data discovery. But that’s where we’re going: shifting from active search to passive discovery based on personalized relevance.
Recently, the exponential increase in data volume, velocity, and business value, coupled with the meteoric rise of low code and citizen data science programs, is making data discovery more important than ever before.
Read also: The truth about industrial digitalization →
In the context of enterprise data management, enabling the right data to be easily discoverable relies on much the same recipe: the right metadata, labeling, linkages to other data, and data cataloging to make it readable by both machines and humans. Outdated manual metadata management is gradually being replaced by active, machine learning-supported metadata practices, used to discover and infer additional metadata from relationships and clustering.
This is why progressive organizations are seeking out data fabric solutions to complement their DWH strategies. Data fabric adds critical context and discovery to existing DWH data assets. Complementing DWH with data fabric is the only way to push through all three steps to true data liberation.