
Spoiler: it does.
We don't mean to dissuade anyone from reading this fully, but allow us to cut to the chase and deliver the payload upfront for those with more limited context windows. A scalable, trustworthy, and safe generative AI implementation needs an excellent RAG solution to feed relevant, trustworthy, and up-to-date information into large language models.
Now, let’s get into the details…
In 2023, ChatGPT was introduced to the World, and soon after, retrieval-augmented generation (RAG) became a ubiquitous term.
Some companies are training Large Language Models (LLMs) from scratch, which requires a large investment. However, there has also been an influx of innovative methods for efficiently fine-tuning models, such as Parameter-Efficient Fine-Tuning (PEFT) [1], QLoRA [2], and prompt tuning [3] have become popular. These techniques allow companies to “train” models on their data without large investments in data sets or hardware for model training.
In addition, context window size (the capacity for LLMs to comprehend and retain knowledge) has greatly increased:

Google has reported that they are experimenting with a context window of 10 million tokens. Given this development, RAG is surely obsolete.
Or is it?
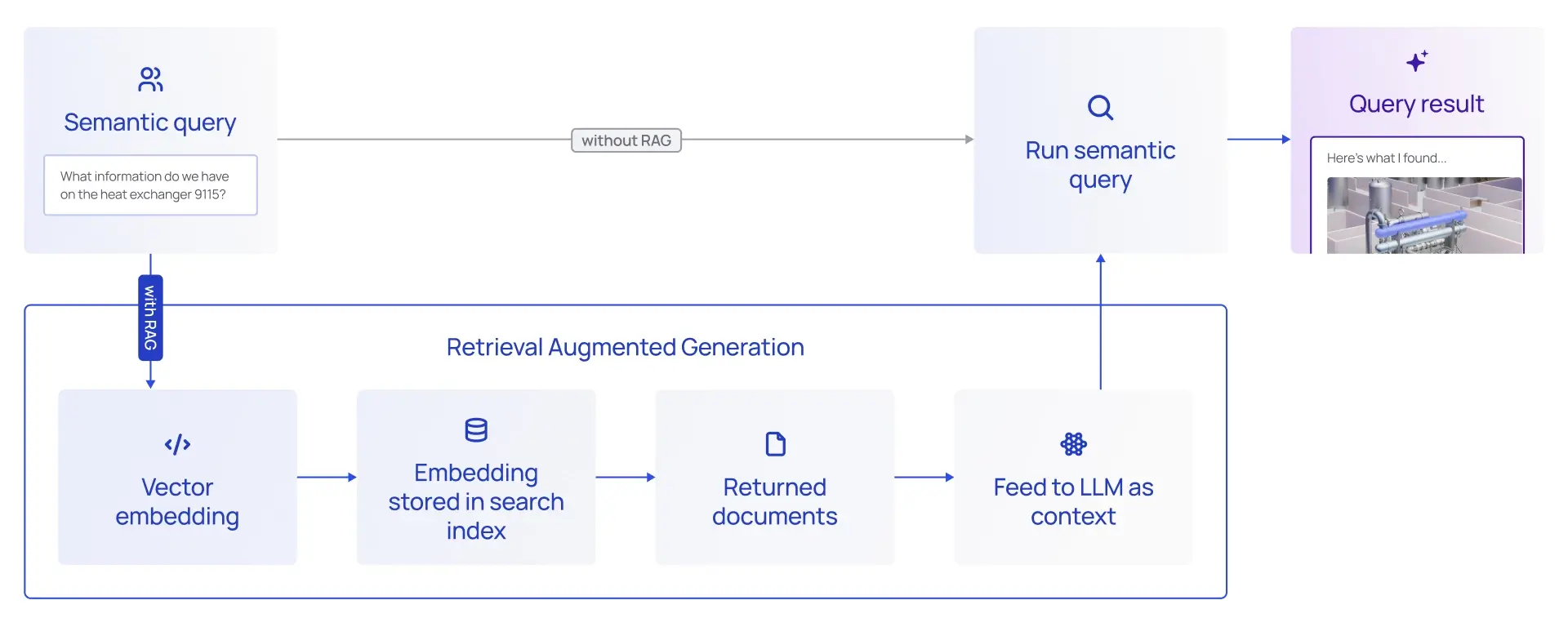
Although the new techniques open up new possibilities, RAG remains a key ingredient in an effective enterprise generative AI framework. There are several reasons why fine-tuning and prompt tuning doesn’t replace the need for a good RAG system:
- Challenges in source attribution: Determining the origin of information from the fine-tuned LLM can be difficult, making it challenging to differentiate between fabrications and factual data.
- Incorporating new information or removing outdated information necessitates retraining or re-fine-tuning, translating to additional time and financial investment.
- Issues with information access control: Lacking mechanisms to manage which data is accessible by different users.
- Ensuring data integrity: Compiling large, accurate data sets demands thorough data verification to guarantee the information remains current and correct.
- Information overload: Like humans overwhelmed by too much information, a large context window holds vast data, but LLMs might struggle to pinpoint what's relevant, increasing the risk of hallucination and inaccuracies [4].
LLMs with a very large context window are a valuable addition to the toolbox, but it's not a universal remedy. Although these models open up for variety of solutions, they have drawbacks:
- Performance: A long context window requires additional processing. This results in a time-to-first token (TTFT is the measurement of how long it takes before the LLM starts “typing” its response) that can be minutes. This is unacceptable for many, or even most, use cases.
- Scalability: With additional processing needs comes reduced scalability. LLM providers operate with quotas. Google allows two requests per minute for Gemini Pro 1.5 (in preview). Anthropic operates with a limit of 10,000,000 tokens per day and 40,000,000 tokens per minute for its top-tier subscription. Although there are always exceptions to such quota restrictions for large enterprises, the numbers are a clear testament to the fact that inference capacity is scarce.
- Cost: A natural consequence of reduced performance and scalability is increased cost. A single request to Anthropic Claude 3 with 200,000 tokens costs about $3.00 USD. This might be an acceptable price for some use cases, but for automated processing pipelines triggering hundreds or thousands of requests on a daily or hourly schedule, the cost will quickly explode.
- Environmental impact: Training LLMs is an extremely power-intensive operation. Although energy efficiency is improving due to new hardware and algorithm improvements, interference remains a compute-intensive operation and will remain so for the foreseeable future. A recent report estimates that energy consumption associated with AI is expected to reach 0.5% of global electricity consumption by 2027 [5].
A scalable, trustworthy, and safe generative AI implementation needs an excellent RAG solution to feed relevant, trustworthy, and up-to-date information to the LLMs.
The Cognite contextualization engine and industrial knowledge graph allow accurate information to be retrieved. The contextualization engine ensures data is connected across source systems, and the new AI service for populating the structured knowledge graphs from unstructured documents ensures the industrial knowledge graph is as complete, accurate, and up-to-date as possible.
Additional services for semantic search enable filtering information based on meaning rather than free-text search. This technique can even find information across multiple languages. These services make it easy to provide the best possible information to the LLMs, reducing the risk of hallucination while keeping the number of tokens required to process low.
The strategies can be integrated with fine-tuning to achieve an optimal balance of timely, relevant updates and a deep understanding of the data. This hybrid approach allows fine-tuning to adapt the LLM to the general data landscape while RAG ensures the provision of current, relevant information, thereby yielding trustworthy outputs with traceable data sources.
The key is to build a representative benchmarking dataset for any generative AI capability to ensure consistent accuracy and performance across a wide range of use cases. Such data sets can also be used to compare the results from different LLMs and assess how the different methodologies mentioned above perform.
In conclusion, while advancements in fine-tuning and training LLMs offer impressive capabilities, the integration of RAG remains indispensable for delivering accurate and reliable AI-driven solutions. By combining innovative fine-tuning techniques with robust RAG systems from Cognite, companies can ensure their AI implementations are powerful and practical. Such a balanced approach enhances the efficacy of generative AI and maintains trustworthiness and relevance in industrial applications.
Learn more about Cognite’s comprehensive suite of Generative AI capabilities: https://www.cognite.com/en/generative-ai
[1] https://www.nature.com/articles/s42256-023-00626-4
[2] https://arxiv.org/abs/2305.14314
[3] https://arxiv.org/abs/2104.08691
[5] https://www.theverge.com/24066646/ai-electricity-energy-watts-generative-consumption