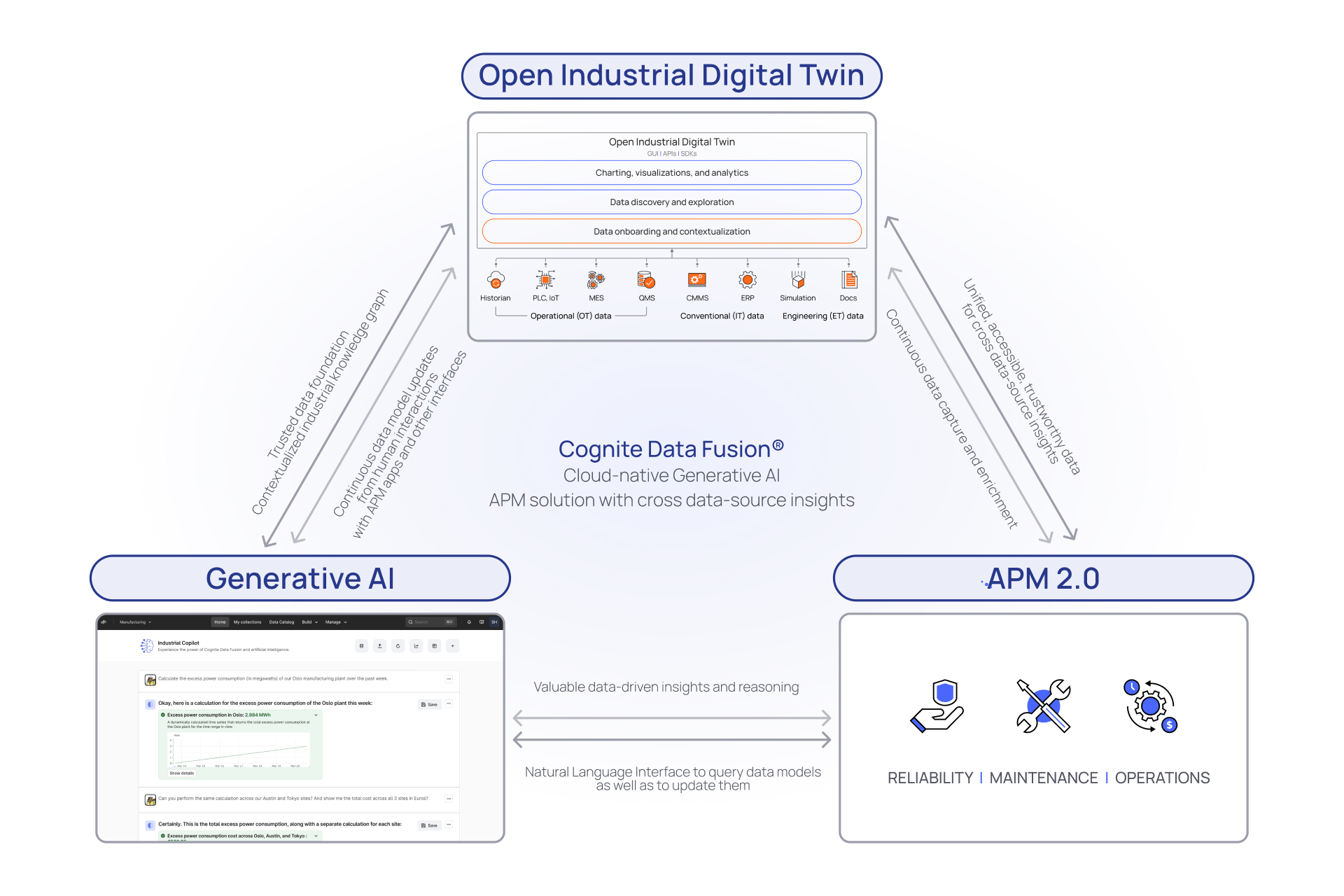
Retraining LLMs to understand the industrial domain like the public internet
Teaching the new dog new tricks
The excitement and innovation surrounding Generative AI and Large Language Model (LLM) solutions like ChatGPT drive the expectation for an industrial digital transformation iPhone moment. These LLMs are the result of training a machine learning model on a large corpus of text data to generate and understand natural language. This unprecedented leap forward in Natural Language Processing allows Generative AI systems to consume, understand, and provide insights into accessible content.
By virtue of their pre-training to perform NLP tasks, LLMs have a vast knowledge base to draw from. However, the content in an LLM’s data stores may be dated (i.e., pre-Sep. 2021) and based solely on content from the public domain. This can limit the source data available for generating a response and potentially lead to out-of-date info or ‘creative’ answers to make up for the information gap (hallucinations). If we can ‘train’ an LLM like ChatGPT on curated, contextualized industrial data, then we could talk to this data as easily as we converse with ChatGPT and have confidence in the basis of the response.
Context matters
The vast data set used to train LLMs is curated in various ways to provide clean, contextualized data. Contextualized data includes explicit semantic relationships within the data that can greatly affect the quality of the model’s output.
Contextualizing the data we provide as input to an LLM ensures that the text consumed is relevant to the task at hand. For example, when prompting an LLM to provide information about operating industrial assets, the data provided to the LLM should include not only the data and documents related to those assets but also the explicit and implicit semantic relationships across different data types and sources.
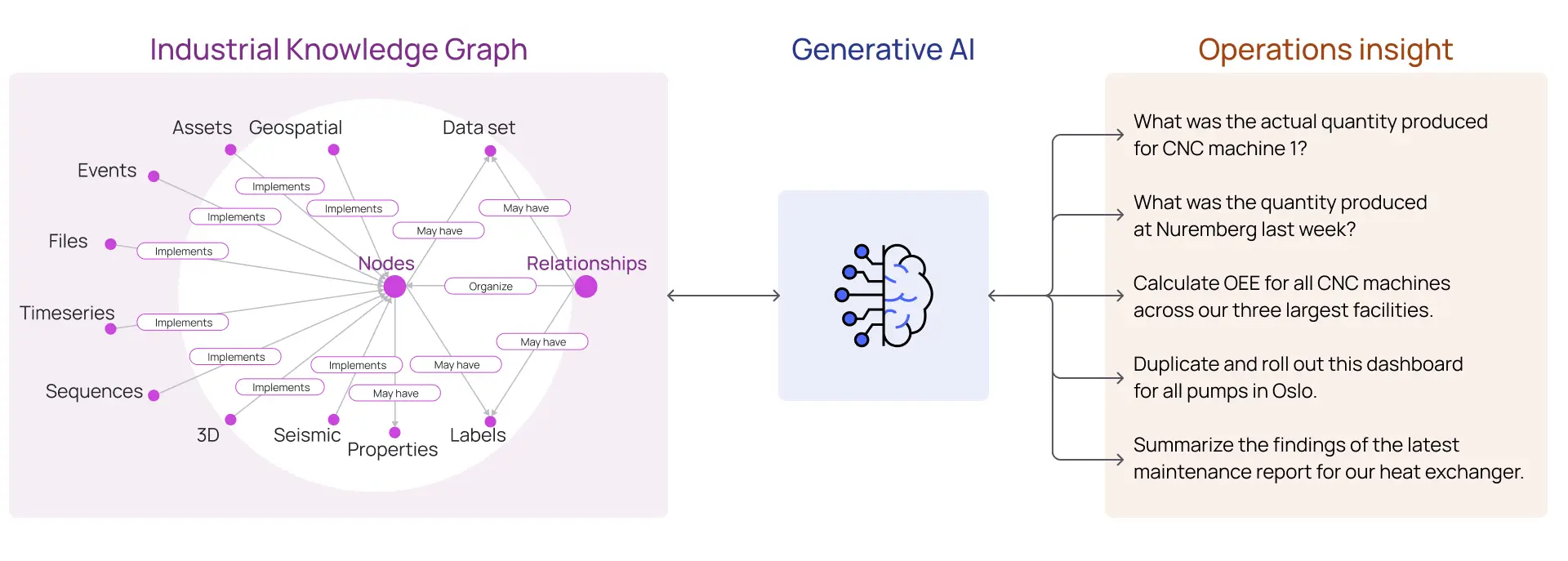
In the process of building the contextualized industrial knowledge graph, data is also processed to improve quality through normalization, scaling, and augmentation for calculated or aggregated attributes. For Generative AI, the old adage of Garbage-In → Garbage-Out applies. Aggregations of industrial data in large data warehouses and data lakes that have not been contextualized or pre-processed lack the semantic relationships needed to ‘understand’ the data and lack the data quality necessary for LLMs to provide trustworthy, deterministic responses.
How do we ‘teach’ an LLM industrial data
An LLM is trained by parceling text data into smaller collections, or chunks, that can be converted into embeddings. An embedding is simply a sophisticated numerical representation of the ‘chunk’ of text that takes into consideration the context of surrounding or related information. This makes it possible to perform mathematical calculations to compare similarities, differences, and patterns between different ‘chunks’ to infer relationships and meaning. These mechanisms enable an LLM to learn a language and understand new data that it has not seen previously.
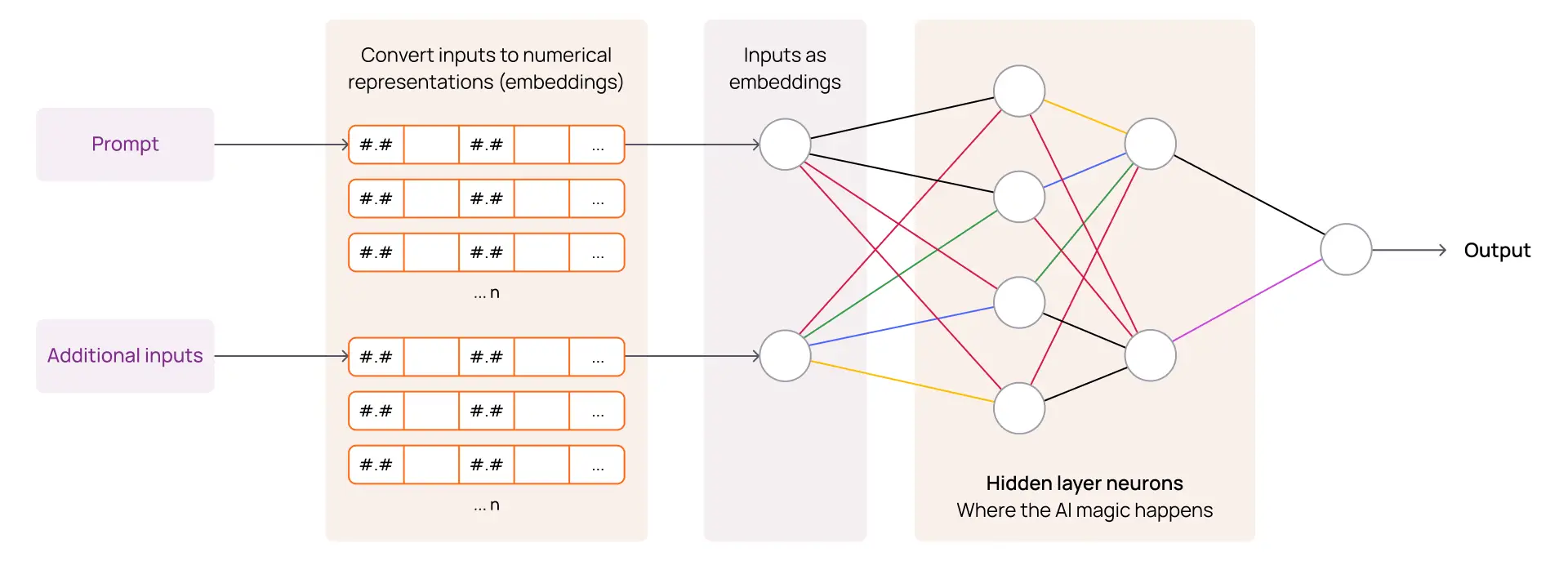
When we ask an LLM a question (prompt) and provide it with additional information to consider when responding (inputs), it processes the prompt by encoding it into these numerical representations using the same techniques used during training. This numerical representation of the prompt is then mathematically compared to the stored embeddings it already ‘knows’ along with encoded embeddings for any additional content provided with the prompt (inputs). The LLM will retrieve embeddings (‘chunks’) deemed relevant and then use them as sources to generate a response.
Option 1 - The CoPilot approach
An Open Industrial Digital Twin comes to life with a comprehensive, contextualized knowledge graph of all industrial data related to an asset. By capturing both the asset data and the semantic relationships between the various asset data types and sources, it becomes possible to build a robust API library that can programmatically navigate and interrogate the asset’s Digital Twin.
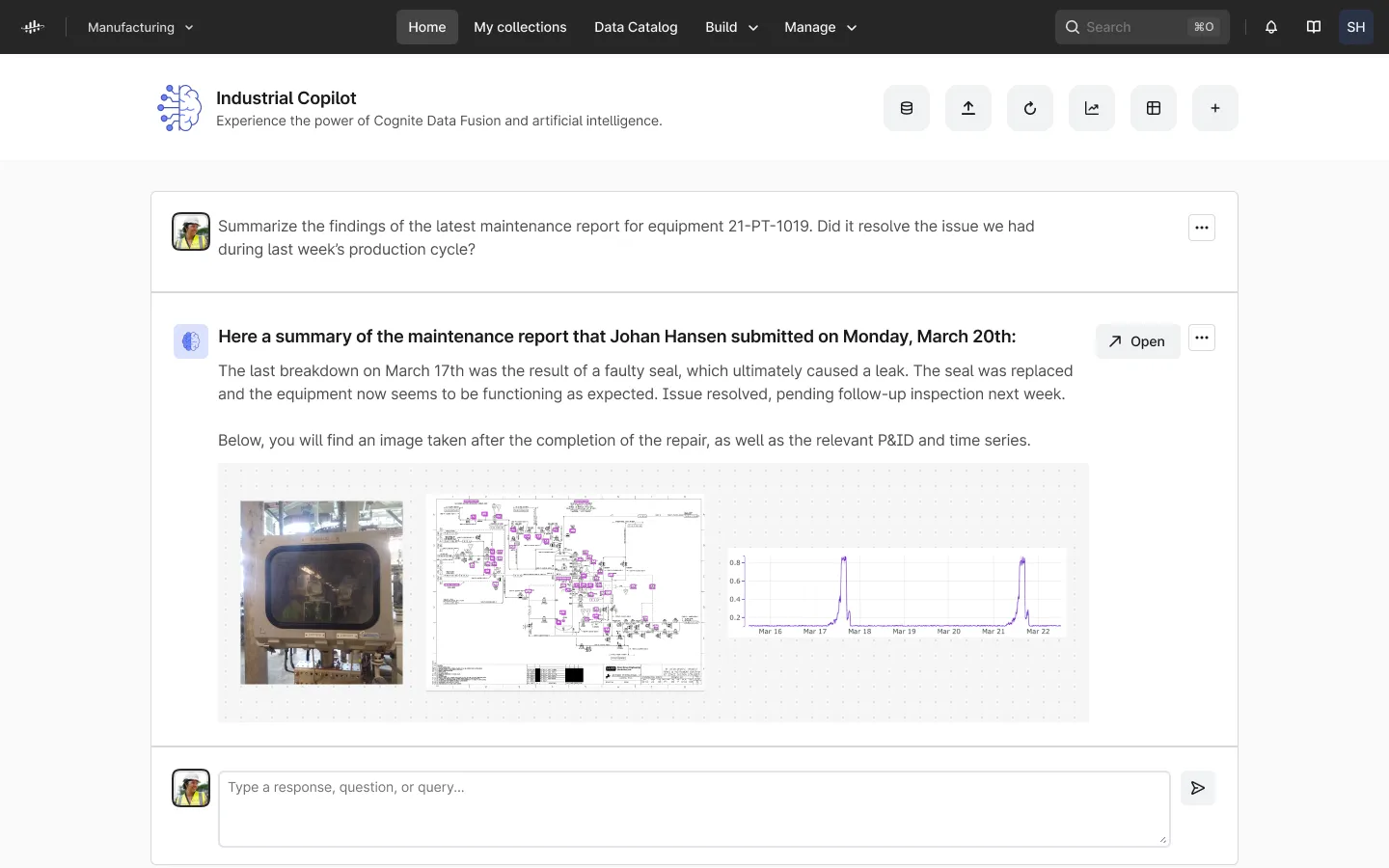
Because LLMs like ChatGPT understand and can generate sophisticated code in multiple languages (i.e., Python, JavaScript, etc.), we can prompt the LLM with a question about our industrial data, and it can interpret the question, write the relevant code using Cognite Data Fusion’s APIs, and execute that code to return a response to the user (see below image for example).
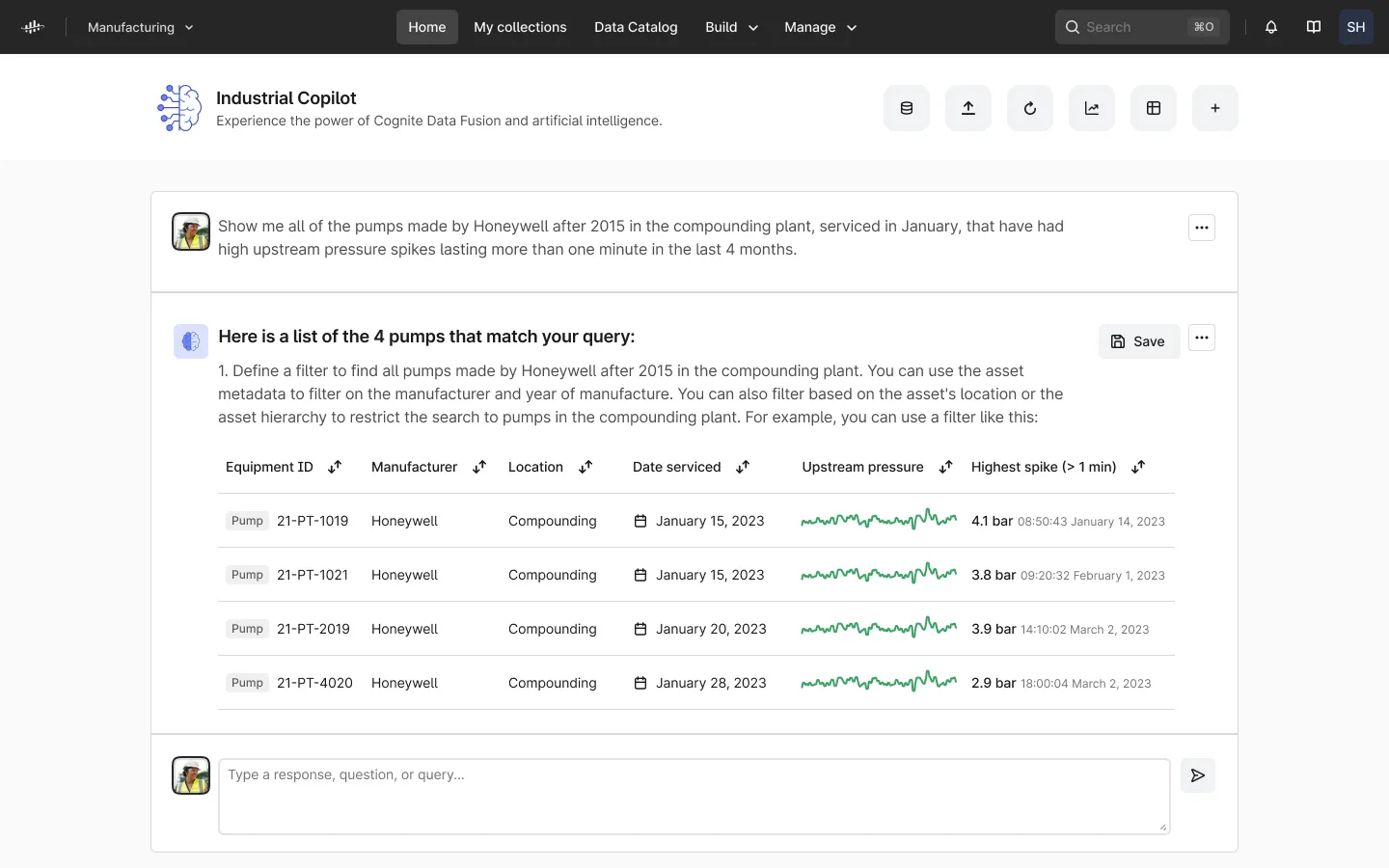
These CoPilot-based approaches leverage the power of natural language to understand and write code based on published API documentation and examples. This is impossible with data lakes or data warehouses where, without a contextualized industrial knowledge graph, there are no API libraries that can be used as a reliable mechanism to access rich industrial data. Additionally, because all data access happens through the APIs, no proprietary data is shared with 3rd parties, and the built-in mechanisms for logging and access control remain intact.
Option 2 - Provide contextualized data directly to the LLM
API libraries available from OpenAI, langchain, and others allow us to leverage the power of the LLM’s natural language processing in conjunction with proprietary data. These libraries enable developers to take data that would normally exceed the limitations of GPT’s input text and perform the same tasks that an LLM would perform. Namely, parse contextualized industrial data into ‘chunks’ that can be turned into embeddings and stored in a private database.
This database can include numerical representations (embeddings) of specific asset data, including time series, work orders, simulation results, P&ID diagrams, as well as the relationships defined by the digital twin knowledge graph. Using these open APIs, we can then send a prompt to the LLM along with access to our proprietary embeddings database so that the LLM will formulate its response based on the relevant content extracted from our own proprietary knowledge graphs.
What does it take to talk to Industrial Data through Generative AI?
An Open Industrial Digital Twin is a prerequisite to enable Generative AI to understand and talk to your industrial data. The data models and contextualized relationships that drive the schema of a digital twin make it possible to provide open, API-driven access to industrial data that LLMs like ChatGPT can use to write and execute software in response to a prompt automagically.
Additionally, contextualized industrial data delivers not only the raw data related to our assets but also the relationships to additional data sources that enable and drive more deterministic interrogations of industrial data by LLM models.
With Generative AI powered by an Open Industrial Digital Twin, we can finally deliver next-generation Asset Performance Management solutions with cross-data-source insights. To be the first to learn more, sign up to our newsletter now and stay up to date on this fast-evolving transformative topic.