

Let’s start with two alarming findings from Gartner:
- “80% of data lakes will not include effective metadata management capabilities, making them inefficient.”
- “Data and analytics organizations that provide agile, curated internal and external datasets for a range of content authors will realize twice the business benefits of those that do not.'
In other words, organizations that implement data catalogs to communicate data context to their internal and external data customers will realize 100% more business value than those who don’t.
What happened to unlocking infinite data-driven potential by liberating data from siloed source systems and integrating it all into one single repository? Let’s examine the anatomy of the paradox.
First, data lakes only store data in an untransformed raw form.
While raw data is theoretically available across realms of immediate, potential, and not-yet-identified interest, active metadata management is often a mere afterthought. It winds up as the technology project’s flagship KPI but lacks enthusiasm or investment from the stakeholders along the way.
Raw data — absent of well-documented and well-communicated contextual meaning — is like a set of coordinates in the absence of a mapping service.
Those lucky few who intuitively understand the coordinates without a map may benefit. For all the rest, it’s the map that provides the meaning. Without a map, coordinates alone are useless to the majority.
Second, data lakes lack contextualization.
While some applications benefit from raw data, most applications — especially low code application development — require data that has undergone some additional layer of contextual processing. This includes aggregated data, enriched data, and synthetic data resulting from machine learning processes.
Here is where the value of data contextualization becomes most pronounced. Aggregated, enriched, and synthetic data delivered as an active data catalog is far more useful to application developers. Strong API and SDK support, designed for use by external data customers, further amplifies the value of this processed data. It’s also something raw data in a large, unified container fails to address.
Data lakes that only store data in an untransformed, raw form offer little relative value. These vast amounts of expensively extracted and stored data are rendered unusable to anyone outside the data lake project team itself. (And too often remain somewhat useless to that team, as well.)
The solution is to complement existing data lake practices with data contextualization
Data contextualization goes beyond conventional data catalog features (see table below) by providing relationship mining services using a combination of machine learning, rules-based decision-making, and subject matter expert empowerment.
Data catalog features:
- allow users and data curators to assign different levels of trust to both raw and processed data sets;
- allow approved users to rate integrated data sets for accuracy;
- offers transparency to actual data usage and query usage;
- single source of truth on which data sets are related and the nature of that relationship;
- track data lineage.
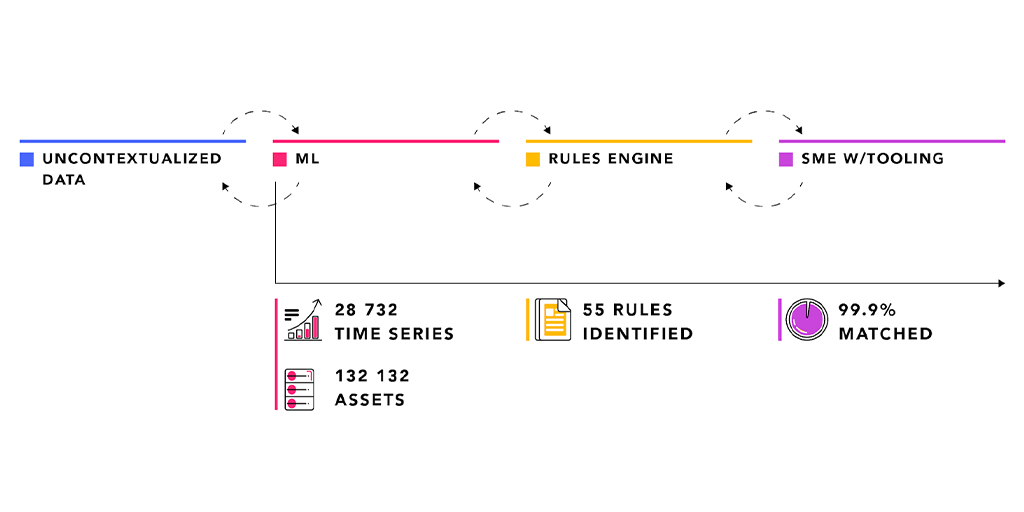
Many mid-sized organizations, operating mostly with IT data, may benefit from a simpler data catalog solution. However, large industrial asset operators dealing with the synthesis of OT and IT data—not least the on-going proliferation of IoT data together with very complicated brownfield data realities—call for an enterprise-grade data contextualization solution.
The most powerful and practical application of data contextualization is the creation of an operational digital twin. This digital representation of an organization’s full, live, connected operational reality is a huge benefit to IT organizations struggling to showcase their data platform capabilities, including data contextualization, to a less data-savvy audience.
Contextualized data generates immediate business value and significant time-savings in many industrial performance optimization applications, as well as across advanced analytics workstreams. (We have found that data science teams are one of the greatest beneficiaries of data contextualization.)
Digital twins are proving to be a fantastic tool for communicating the potential value and opportunities presented by liberated, enriched, and contextualized data. The distance between a data lake and a digital twin may not be that far after all. Contextualization, offered as a service for data already aggregated in one place, offers an instant upgrade.